10 must-know terms and components for search engine development

Almost all online traffic is dictated by search engines and your search engine is often the first interaction a user has with your company. The user experience of search engines is quite simple: type what you’re looking for, hit enter and choose from a list of results. However, there are many factors and intricate parts that go into making that search engine find and rank results from thousands, or even millions of pages in a matter of seconds.
For those looking to learn more about search engines or search relevance, below are 10 must-know search engine terms and components.
1. Search relevance
You may hear this term a lot in machine learning, but search relevance is simply a measure of how closely the results of a search engine query match what the user was looking for. In other words, it refers to the relevancy of the fetched search results. If the search engine results pages match the user’s query accurately, the search engine has good search relevancy. If the results are completely off and not what the user was looking for, the search engine has poor search relevancy.
2. Recall
When you type a query into a search engine, the algorithm’s job is to return all relevant items matching your query. Recall refers to the number of relevant items that were actually returned versus the total number of relevant items that exist. For example, imagine you type “coffee grinder” into a search engine on an eCommerce site. If the search engine returns nine items, but the site actually had 10 coffee grinders for sale, the search results had a 90% recall.
The easiest way to achieve 100% recall would be to simply have the algorithm return everything. That way, you’re guaranteed to return 100% of the relevant items. However, this would result in low precision and a poor search engine overall.
3. Precision
Whereas recall is the number of returned relevant items over the number of existing relevant items, precision is the number of relevant items over the total number of items (relevant or not) returned.
Going back to the coffee grinder example, let’s say you search for coffee grinders and the search engine returns 20 items. However, of those 20 items, only nine were actually coffee grinders and the remaining 11 had nothing to do with coffee grinders. Here, the precision is nine over 20, which is a little under 50%.
4. The F-measure
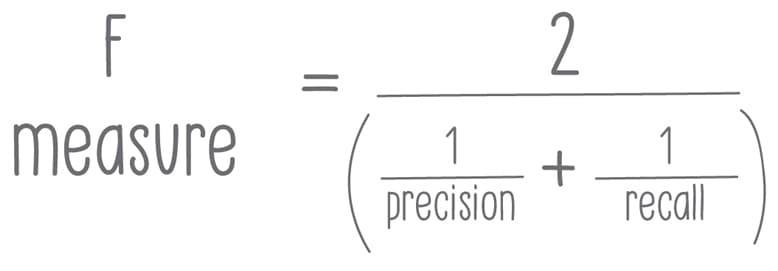
The F-measure, also known as the F-score or F1 score, is one way to judge or score search relevance. While there are multiple iterations of this, one common and simple formula for the F-measure is two divided by one over precision plus one over recall.
5. Part-of-speech tagging
One important element of search engines is the ability to properly analyze text. Part-of-speech (POS) tagging, also known as POS tagging, is one factor that goes into text analysis. Search algorithms need to properly analyze the words in a query to understand what the user is looking for. POS tagging is the process of labeling different words or terms in a search query based on their function. The machine must be trained to recognize the different parts of speech (nouns, adjectives, etc.) and identify the main subject of the query and its modifiers.
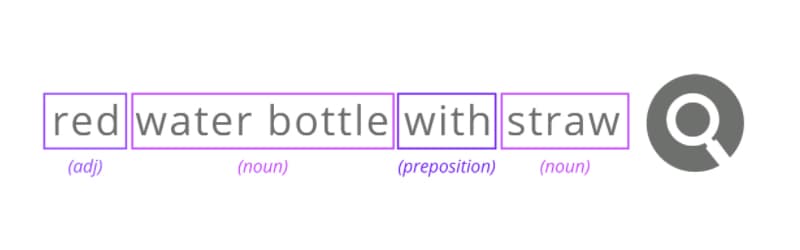
In the above example, there are a variety of ways an untrained machine could mishandle the query. For instance, the user doesn’t want a bottle containing red water, they want a water bottle that is red. After training your search engine with enough accurate data, the machine will be able to identify content words and function words correctly. Good search engines can respond to queries written in a variety of ways, grammatically accurate or not (e.g., water bottle with straw red, water bottle red with straw).
Training your search engine to accurately identify different words and their functions requires a large amount of data. This data must be accurately labeled by trained human annotators. There are many reasons why human intervention is necessary for search engine training, but perhaps the most important is the subjective nature of language when it comes to search queries.
The quality of your search engine is heavily reliant on the accuracy of the data you feed it. Building a search engine with erroneous data is like trying to teach with an outdated textbook: your students may have learned something, but what they have learned won’t match reality. Likewise, if a search engine is trained with improperly tagged data, the results it fetches won’t match what the user was looking for.
6. Term weighting
Term weighting is the process of assigning each term or word a numerical value of importance which is then reflected in the fetched results of the search query. For instance, nouns in a search query would be given a heavier weight than adjectives, or words preceding “with” would be given a heavier weight than the words following it.
In the previous query example, “red water bottle with straw,” the most important part of the query is “water bottle.” In the case where there aren’t red water bottles, you don’t want the search engine to return results of red straws.
While that example was simple, term weighting can become quite complicated. If there are no red water bottles with a straw, should the search engine prioritize results of red water bottles without straws or non-red water bottles with straws? This balancing act of what should take priority is the key to making a strong search engine.
7. Term frequency
The ranking of search results relies on a variety of elements, one of the most obvious being term frequency. Simply put, term frequency is the number of times a term in the search query appears in the fetched document or page. For example, if you search “best romance film,” the page with the highest amount of those three individual words has the highest term frequency (see table below).
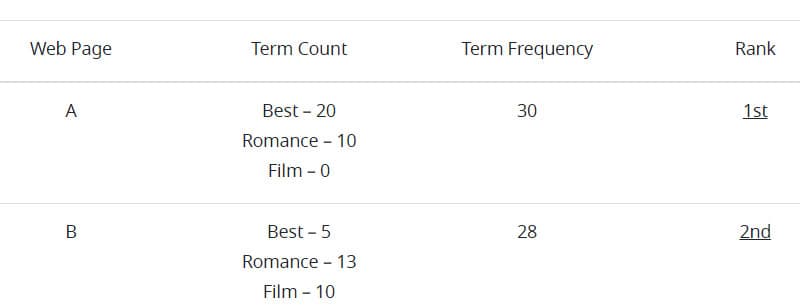
However, as illustrated in the table above, ranking results on term frequency alone can lead to issues. Page A (ranked first) could be about the best romance books, poems and television shows, but not necessarily romance films. Page B, which is likely more relevant, is ranked second. This could be due to a variety of reasons, including differences in total word count, but one way to weed out irrelevant pages is to apply inverse document frequency.
8. Inverse document frequency
While term frequency is a good way to judge how related a page or document is to the query, some words in the query should carry less weight. If you search for “best romance film,” the word “best” should carry less weight because there are millions of pages that include it.
One way to offset the scoring of these less important words is by using inverse document frequency. Whereas term frequency is equal to the number of times a term appears on a page, inverse document frequency is equal to the number of times a word appears on a page divided by the total amount of documents or pages that the term appears in.
In the table below, since the words “best” and “romance” appear in both pages, they are given a lower weight than the word “film,” which only appears in one page. Although Page A has a term frequency score of 30, it has an inverse document frequency score of 15.
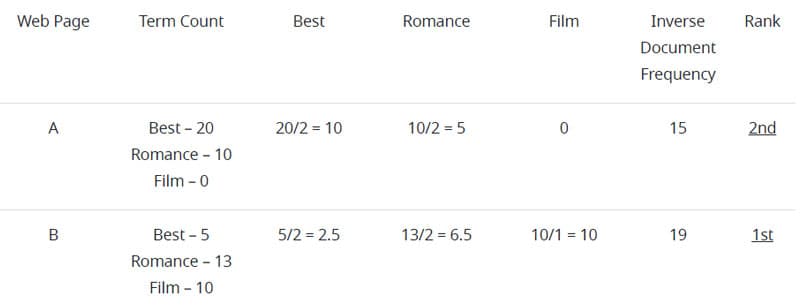
Keep in mind that the above example is simplified, as most search engine results will include hundreds to thousands of pages, rather than just two.
Inverse document frequency can help even the playing field, but it still isn’t enough to give the most accurate results. For example, if there was a 10,000-word article about the best films, that article might be highly ranked based on the sheer volume of the terms “best” and “film” alone, despite the fact that a 600-word listicle about the best romance films would be more relevant. Therefore, additional scoring elements should be implemented to provide more accurate results.
9. Keyword proximity
Keyword proximity is another scoring element used in search engines. Search queries often include a combination of words and as the name suggests, keyword proximity is the distance between each of the individual keywords that occur in the fetched pages. Using the “best romance film” query example, a page that has the sentence “A Walk to Remember is the best romance film,” would be given additional ranking points over a page that says “Nicholas Sparks has signed a film deal for his best-selling romance novel.”
10. Stop words
Stop words are the words in a search query that aren’t taken into account at all when ranking search results. Certain words in a search query are so common that they’ll appear on almost every document or page. For example, when searching for “the best romance film,” there would be little point in giving “the” any weight in the query since “the” appears many times on almost every English web page and document in existence. Implementing stop words is another way to weed out irrelevant search results.
Search engine development is one of the most important applications of machine learning. If you’re looking for more reading on search engines, be sure to check out our search relevance 101 article.




