Five types of image annotation and their use cases
Looking for information on the different image annotation types? In the world of artificial intelligence (AI) and machine learning, data is king. Without data, there can be no data science. For AI developers and researchers to achieve the ambitious goals of their projects, they need access to enormous amounts of high-quality data. In regards to image data, one major field of machine learning that requires large amounts of annotated images is .
What is computer vision?
Computer vision is one of the biggest fields of machine learning and AI development. Put simply, computer vision is the area of AI research that seeks to make a computer see and visually interpret the world. From autonomous vehicles and drones to medical diagnosis technology and facial recognition software, the applications of computer vision are vast and revolutionary.
Since computer vision deals with developing machines to mimic or surpass the capabilities of human sight, training such models requires a plethora of annotated images.
What is image annotation?
Image annotation is simply the process of attaching labels to an image. This can range from one label for the entire image, or numerous labels for every group of pixels within the image. A simple example of this is providing human annotators with images of animals and having them label each image with the correct animal name. The method of labeling, of course, relies on the image annotation types used for the project. Those annotated images, sometimes referred to as ground truth data, would then be fed to a computer vision algorithm. Through training, the model would then be able to distinguish animals from unannotated images.
While the above example is quite simple, branching further into more intricate areas of computer vision like autonomous vehicles requires more intricate image annotation.
What are the most common image annotation types?
Wondering what image annotation types best suit your project? Below are five common types of image annotation and some of their applications.
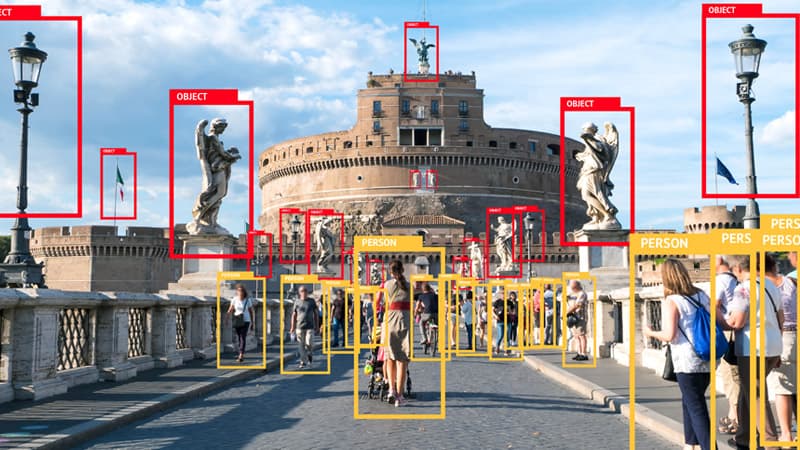
1. Bounding boxes
For bounding box annotation, human annotators are given an image and are tasked with drawing a box around certain objects within the image. The box should be as close to every edge of the object as possible. The work is usually done on custom platforms that differ from company to company. If your project has unique requirements, some companies can tweak their existing platforms to match your needs.
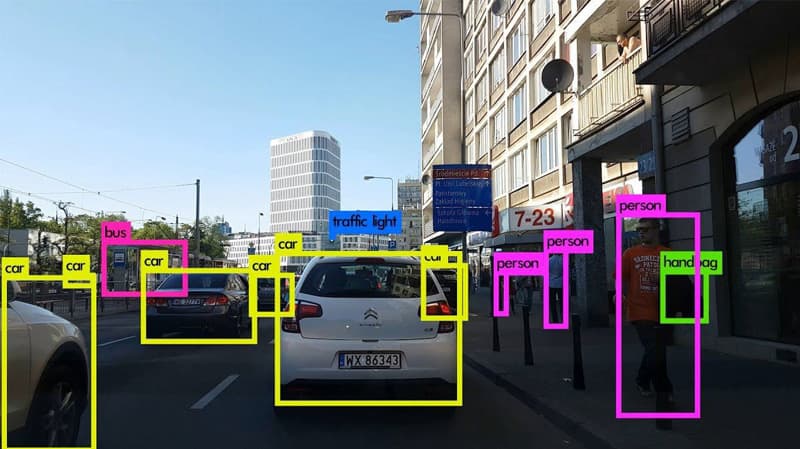
One specific application of bounding boxes would be autonomous vehicle development. Annotators would be told to draw bounding boxes around entities like vehicles, pedestrians and cyclists within traffic images.
Developers would feed the machine learning model with the bounding-box-annotated images to help the autonomous vehicle distinguish these entities in real-time and avoid contact with them.
2. 3D cuboids
Much like bounding boxes, 3D cuboid annotation tasks annotators with drawing a box around objects in an image. Where bounding boxes only depicted length and width, 3D cuboids label length, width and approximate depth.

With 3D cuboid annotation, human annotators draw a box encapsulating the object of interest and place anchor points at each of object’s edges. If one of the object’s edges are out of view or blocked by another object in the image, the annotator approximates where the edge would be based on the size and height of the object and the angle of the image.
3. Polygons
Sometimes objects in an image don’t fit well in a bounding box or 3D cuboid due to their shape, size or orientation within the image. As well, there are times when developers want more precise annotation for objects in an image like cars in traffic images or landmarks and buildings within aerial images. In these cases, developers might opt for polygonal annotation.

With polygons, annotators draw lines by placing dots around the outer edge of the object they want to annotate. The process is like a connect the dots exercise while placing the dots at the same time. The space within the area surrounded by the dots is then annotated using a predetermined set of classes, like cars, bicycles or trucks. When assigned more than one class to annotate, it is called a multi-class annotation.
4. Lines and splines
While lines and splines can be used for a variety of purposes, they’re mainly used to train machines to recognize lanes and boundaries. As their name suggests, annotators would simply draw lines along the boundaries you require your machine to learn.
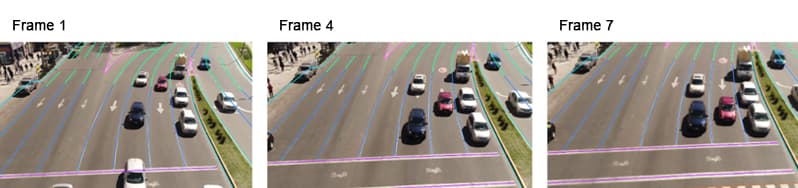
Lines and splines can be used to train warehouse robots to accurately place boxes in a row, or items on a conveyor belt. However, the most common application of lines and splines annotation is autonomous vehicles. By annotating road lanes and sidewalks, the autonomous vehicle can be trained to understand boundaries and stay in one lane without veering.
5. Semantic segmentation
Whereas the previous examples on this list dealt with outlining the outer edges or boundaries of an object, semantic segmentation is much more precise and specific. Semantic segmentation is the process of associating every single pixel in an entire image with a tag. With projects requiring semantic segmentation, human annotators will usually be given a list of pre-determined tags to choose from with which they must tag everything on the page.

Using similar platforms used in polygonal annotation, annotators would draw lines around a group of pixels they want to tag. This can also be done with AI-assisted platforms where, for example, the program can approximate the boundaries of a car, but might make a mistake and include the shadows underneath the car in the segmentation. In those cases, human annotators would use a separate tool to crop out the pixels that don’t belong. For example, with training data for autonomous vehicles, annotators might be given instructions like, “Please segment everything in the image by roads, buildings, cyclists, pedestrians, obstacles, trees, sidewalks and vehicles.”
Another common application of semantic segmentation is medical imaging devices. For anatomy and body part labeling, annotators are given a picture of a person and told to tag each body part with the correct body part names. Semantic segmentation can also be used for incredibly specialized tasks like tagging brain lesions within CT scan images.
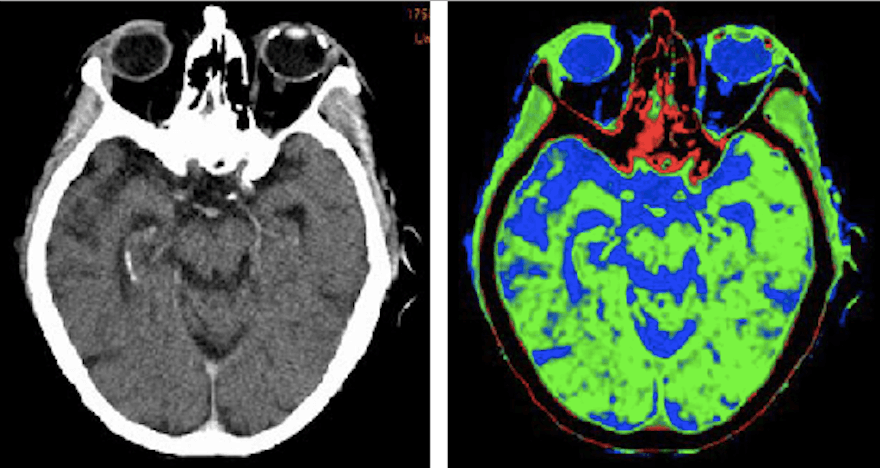
Via semanticscholar.org, original CT scan (left), annotated CT scan (right).
Regardless of the type of image annotation or the use case, a partner you can trust to help get your next machine learning project off the ground is of tremendous value. Get started today by contacting our AI Data Solutions team.




