Your complete guide to image segmentation

Computer vision (CV) has advanced rapidly over the last few years. At its core, it is the technology that allows machines to process their surroundings as humans do. While the human brain is naturally capable of multi-tasking and making quick decisions, transferring this capability to machines has required decades of research and experimentation. Today, we can build computer vision models that can detect objects, determine shapes, predict object movements and take necessary actions based on data. Self-driving cars, aerial mapping, surveillance applications and various other extended reality technologies like AR and VR are all a result of the progress made in computer vision models.
The most popular method used for training CV applications or implementing perception models is via labeling objects in an image, commonly referred to as object detection. The more granular method of training models at the pixel level is segmentation. Read on to explore the different types of image segmentation.
What is image segmentation?
All image annotations initiate a particular function for a machine learning (ML) algorithm’s output. To understand image segmentation, let’s look at the different types of annotations using simple examples.

Image A has a single dog classification tag that helps object classifier models identify if a particular image in a sequence contains a dog.
Image B has only one dog identified via a 2D bounding box annotation that allows an object detection and localization model to predict a dog and its location in the given image.
Image C has both a dog and a cat with multiple 2D bounding boxes that could help a multi-object detection and localization model to detect the animals and understand where exactly they are located in the image.
Although the 2D bounding box annotations in Image B and Image C help models detect object classes and predict accurate locations, they do not provide an accurate representation of what the image consists of. This is where segmentation becomes critical for complex computer vision models.
Segmentation partitions each pixel in a given image to provide an accurate representation of the object shapes. Every pixel in the image belongs to at least one class, as opposed to object detection where the bounding boxes of objects can overlap. This provides a more granular understanding of the contents of the image. The goal here is to recognize and understand what an image contains at the pixel level. To this effect, annotators are given the task of separating an image into multiple sections and classifying every pixel in each segment to a corresponding class label.
For example, in Image B and Image C, you’ll see that object detection only showcases the classes but tells us nothing about the shape. In Image D, however, segmentation gives us pixel-wise information about the objects along with the class.

The essential guide to AI training data
Different types of image segmentation tasks
Image segmentation tasks can be classified into three groups based on the amount and type of information they convey: semantic, instance and panoptic segmentation. Let’s explore the different types of image segmentation tasks.
Semantic (non-instance) segmentation
Semantic segmentation, also known as non-instance segmentation, helps specify the shape, size and form of the objects in addition to their location. It is primarily used in cases where a model needs to definitively know whether or not an image contains an object of interest and also what sections of the image don’t belong to the object. Pixels belonging to a particular class are simply classified as such with no other information or context taken into consideration.
Instance segmentation
Instance segmentation tracks the presence, location, number, size and shape of objects in an image. The goal here is to understand the image more accurately with every pixel. Therefore, the pixels are classified based on “instances” rather than classes to segregate overlapping or similar objects based on their boundaries.
Non-instance vs. instance segmentation
The key difference between non-instance and instance segmentation can be understood with the help of the following example.

In Image E, there are no instances. All objects are simply labeled as “Dog” and the pixels are marked in pink. In Image F, the instances are uniquely marked. All objects are labeled independently as Dog 1, Dog 2 and so on, along with varying colors to segregate the objects of interest.
Pan-optic segmentation
Panoptic segmentation is by far the most informative task since it blends both semantic and instance segmentation, providing granular information for advanced ML algorithms.
Take a look at the different types of segmentation in the example below.
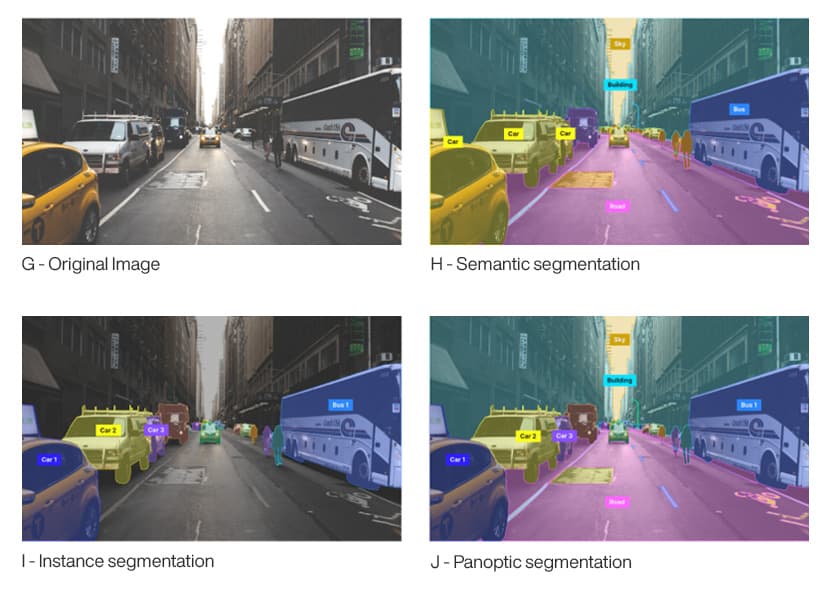
Image H showcases segmented classes without instances and is tagged as Car, Building, Road, Sky. Each pixel of an object class is assigned a different color to classify the object pixels.
Image I illustrates instance segmentation where segmented classes are related to specific objects. For example, all cars are tagged as Car 1, Car 2, Car 3 (instances) and each pixel is assigned a different color to segregate the object region.
Image J has a combination of segmented classes along with instances Car 1, Car 2, Car 3, and non-instance classes like Sky, Road, etc.
Popular computer vision applications that use image segmentation
Segmentation is used for the granular understanding of images in a variety of industries. It is especially popular in the autonomous driving industry, as self-driving cars perform complex robotics tasks and require a deep understanding of their surroundings. In this area of research and experimentation, information about every pixel is critical and may influence the accuracy of the perception model.

Another common application is the use of full-pixel, non-instanced segmentation when training perception models to identify objects of interest from faraway cameras for geospatial applications.

Other geospatial applications using semantic segmentation include geosensing for land usage mapping via satellite imagery, traffic management, city planning and road monitoring. Land cover information is also critical for various applications that monitor areas of deforestation and urbanization. Typically, each image pixel is segmented and classified into a specific type of land cover, for example, urban areas, agricultural land, water bodies, etc.

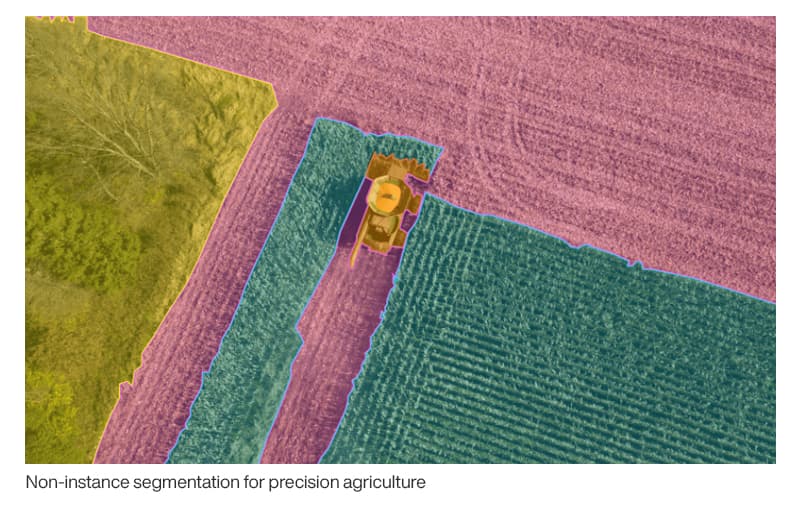
Semantic segmentation of crops and weeds assists precision farming robotic initiatives in real-time to trigger weeding actions. These advanced computer vision systems significantly reduce manual monitoring of agricultural activities.
For fashion eCommerce brands, semantic segmentation enables the automation of tasks like clothing parsing that are typically very complex. Fine-grained clothing categorization requires higher levels of judgment based on the semantics of the clothing, variability of human-poses, and the potentially large number of classes and attributes involved.

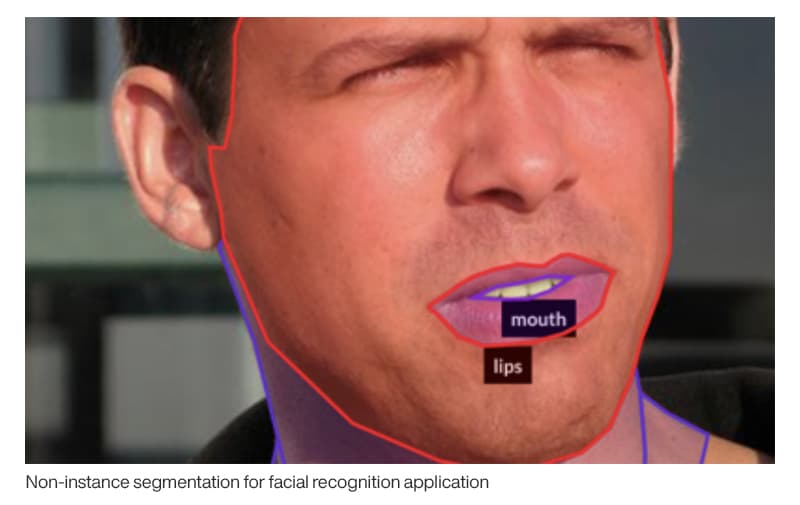
Facial feature recognition is another common area of interest. The algorithms help estimate gender, expression/emotion, age, ethnicity and more by studying facial features. Factors like varying lighting conditions, facial expressions, orientation, occlusion and image resolution increase the complexity of these segmentation tasks.
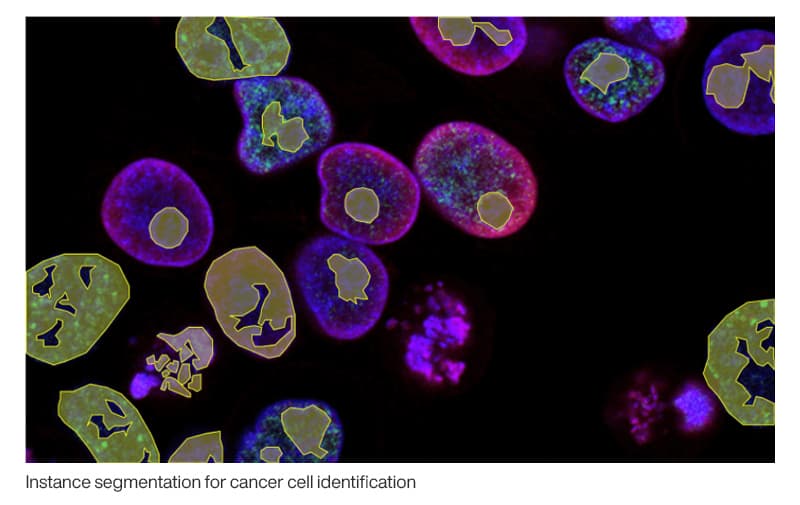
Computer vision technologies are also growing in popularity in the healthcare industry in relation to cancer research. A common use case where segmentation is applied is when instances are used for detecting the shapes of cancerous cell(s) to expedite diagnosis processes.
Looking to start your segmentation project? Reach out to our experts who can help you create accurately labeled data with speed and scale.




