What’s the difference between AI, machine learning and deep learning?
When it comes to machine learning, the media spotlight is both a blessing and a curse. Although it’s great that artificial intelligence (AI) has captivated the general public, the way that the media discusses it often obscures the meaning of the term entirely. Despite good intentions, intense media coverage has led to the proliferation of buzzwords and the interchangeable use of distinct concepts. It’s even possible to see simple algorithms mistaken for the kind of conscious machines that we see in sci-fi movies. To make matters worse, the sheer depth and breadth of the field of AI means that its boundaries and sub-divisions are, to some extent, still up for debate.
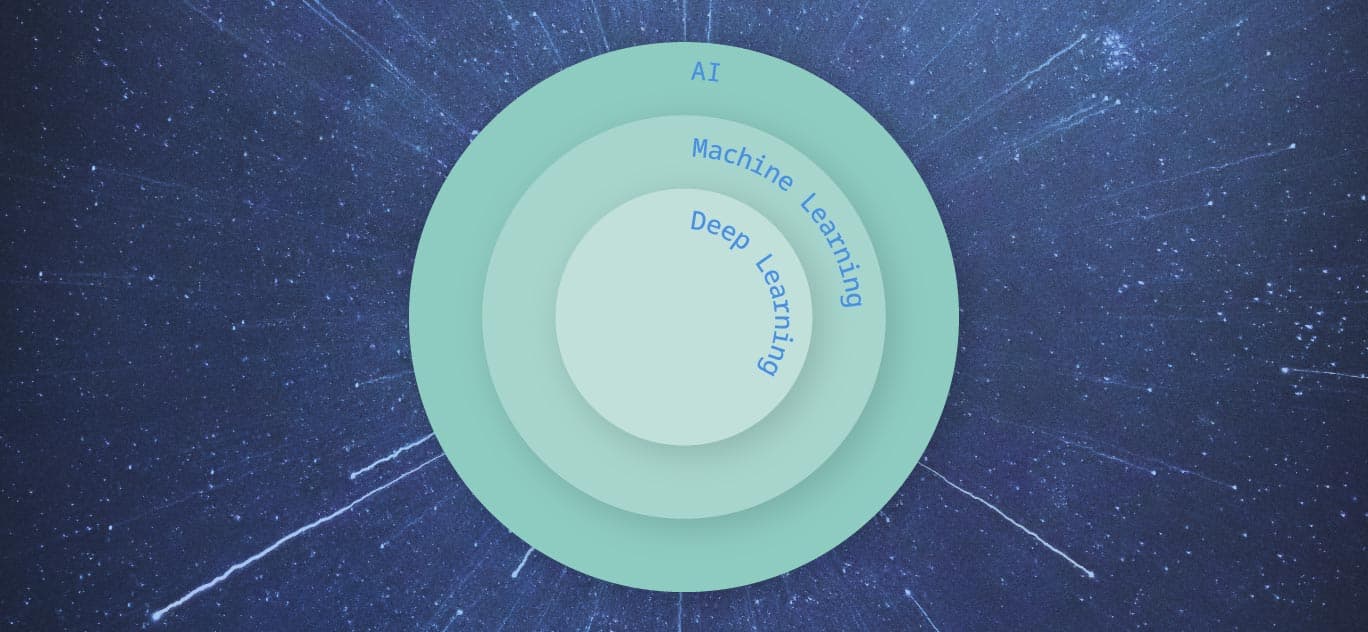
In fact, there are some subtle differences between AI and its related fields: machine learning and deep learning. It’s vital that you clearly understand all of them if you want to make a successful foray into the world of AI. With this in mind, let’s have a look at these three core terms and what data scientists are actually talking about when they use them.
What is artificial intelligence?
AI is the oldest and broadest of the three terms mentioned above. Essentially, it’s the umbrella term for any technology that tackles complex problems in a human-like manner, or that generally acts in a human-like way. AI projects aim to take human approaches to tasks and build upon them, so that the resulting machine can perform these tasks as well as — or even better than — humans. AI research is most prevalent in areas where machines have previously struggled to make progress, such as communication, reasoning or movement around a space.
The main difference between an AI algorithm and a traditional computer algorithm lies in the way that their rules are created. In a traditional algorithm, a developer will set specific rules that define an output for each type of input that the software receives. In contrast, AI algorithms are designed to build out their own system of rules, rather than have those rules defined for them by a developer. Through this approach, it has become possible for computers to start doing tasks that were traditionally dependent on humans, such as customer service, textual analysis or driving cars.
There’s no doubt that these developments are extremely exciting, but it would be a mistake to conflate the field of AI with the conscious, omniscient robots we see in science fiction. The ultimate end goal of AI research is to eventually build similar machines, often referred to as strong AI. These machines would theoretically be able to learn new tasks independent of human instruction. However, it’s still very much up for debate whether this is even possible. We simply haven’t had the breakthroughs that would enable us to start on such a project — and there’s no way of knowing when they will happen, if they happen at all.
Instead, all AI applications today can be classified as weak AI. This means that the algorithm is only learning what it has been told to learn within an extremely specific field. For example, a virtual assistant can identify verbal commands with ease and can also learn to recognize new, previously unheard variations of these commands. However, it can’t learn to tag you in your photos or drive your car for you. As a result, all the talk of the imminent rise of machines is actually pretty unhelpful. While strong AI and machine consciousness are interesting topics of discussion, they are largely irrelevant to any real work that is being done by researchers in the field.
Having said that, AI research argues that if your description of a task is precise enough, a model can be built to simulate any feature of intelligence. As a result, it’s unsurprising that some of the best AI algorithms have been developed to tackle specialized tasks, such as playing certain video games. These algorithms use a range of fast processing techniques to understand the patterns and relationships behind annotated datasets. Through a combination of highly specific task instructions and large training datasets replete with focused tags, it’s entirely possible to build algorithms that can outstrip human performance in a variety of areas that were previously off-limits to computers.
The rapid growth of AI is largely due to the machine learning processes that are used to develop these algorithms. There are, however, some key differences between the two that we’ll explore below.
What is machine learning?
Machine learning is generally considered to be a subset of AI. However, it’s pretty common to hear the two terms used interchangeably. The reason for this is simple. Almost all AI applications that exist today have been built through machine learning. AI is the grand vision of intelligent machines, while machine learning is the models, processes, and supporting technology that we’ve been using to try to get there.
Of course, it’s possible that there may be other ways to create artificially intelligent machines. Unfortunately, we have yet to make any meaningful progress with other methods. While the concept of AI is fuzzy enough to leave room for them, the real progress we are seeing today is the product of machine learning processes.
This field has some key characteristics which differentiate it from more traditional areas of computer science. The most important of these lies in the way that machine learning algorithms are trained. Consider something like facial recognition. In order for a traditional algorithm to recognize and label a single face within a picture, it would need to receive instructions on a pixel-by-pixel level. The developer would have to write code in which an extremely precise configuration of thousands of pixels results in a certain label output. Not only that, but every single possible configuration of pixels that could make up a human face would need to be coded into the algorithm.
Building a facial recognition algorithm in this way is essentially impossible due to the sheer number of variables here, as well as the unpredictable input that such a system receives. Instead, machine learning algorithms are trained in a way that reframes the problem. In training, the algorithms are fed with a huge number of data points containing correct input-output combinations. From this, they are then able to extrapolate their own system of rules to perform the task.
Machine learning algorithms are also able to learn independently from new input. This allows them to improve without the need for human intervention. This is absolutely crucial to many of AI’s defining use cases, such as computer vision and machine translation.
At this point, it’s difficult to identify any AI algorithms that have been built using techniques that fall outside of machine learning. There are a few edge cases that have been developed using comprehensive systems of rules built out by humans, but as we’ve discussed, it may be hard to classify these as AI. The gray areas here are one of the big reasons why these two terms are used almost interchangeably by many researchers and developers.
There is, however, one more term that is also thrown into the mix of AI conversations: deep learning.
What is deep learning?
In a nutshell, deep learning is all about scale. As computing power and the availability of training data has increased, researchers have been able to take machine learning processes further than ever before. Eventually, this led to the use of a new term: deep learning. To fully understand its meaning, it’s essential to first know a little bit about neural networks.
As the name suggests, neural networks are a type of machine learning that attempts to simulate the processes of the human brain when it comes to performing tasks. At a high level, this process can be split into the following steps:
- Break down the input training data into useful attributes, which can then be approximated to cells with an input of 0 or 1. For example, in facial recognition, each input photo could be broken down into pixels, with each pixel assigned a value.
- Connect each of these cells to a layer of nodes, giving each connection an appropriate weight.
- Each node then holds the calculation of the cell’s value, multiplied by its weight. Perform these calculations many more times through further layers of nodes.
- The final layer of nodes connects to an output data layer. By doing a final set of calculations using weights and nodes, then putting the resulting figures through a mathematical function, the output layer can then represent the probability of each possible answer.
The neural network itself is the resulting mesh of connections and pathways between these nodes. The key differentiator between machine learning and deep learning is in the number of layers of nodes that the input data passes through. Until fairly recently, it was only possible to connect a few layers of nodes due to simple computing limitations. However, as technology has improved, it has become possible to build ‘deeper’ neural networks with more hidden layers. This is the kind of model that data scientists mean when they talk about deep learning.
This increase in the number of layers has a profound impact on results, which also play a role in distinguishing deep learning and machine learning. By performing a larger number of calculations and making a greater number of connections, the accuracy of deep learning predictions is usually far better than those of simpler models. With more weights and connections by orders of magnitude, it’s possible for the machine to make extremely fine adjustments based on new input data.
This also has the effect of creating a longer improvement time frame for deep learning models. Machine learning improvement has a tendency to plateau after a critical amount of training data has been reached. With deep learning, however, the sheer number of weights to adjust means that this critical point is much further away — giving the model more space to learn. In fact, a large amount of training data is necessary to reap the full benefits of a deep learning model. Without this extra data, it’s a waste of computing power and time to try to build out such a complex solution.
For many people building models, this increased improvement potential is critical to the success of their project. As with much of AI, deep learning is driven by the desire to solve extremely complex problems. Its success is what sets it apart.
Still confused?
Despite the similarities between AI, machine learning and deep learning, they can be quite clearly separated when approached in the right way. AI is the grand, all-encompassing vision. Machine learning is the processes and tools that are getting us there. Finally, deep learning is machine learning taken to the next level, with the might of data and computing power thrown behind it. With this in mind, it’s possible to begin navigating through this complex, exciting field — and figuring out which processes will help to build out your own project. To learn more and to put these learnings into practice,check our our AI Data Solutions.




