We tested 10 speech-to-text models — Here's what to know when choosing STT for voice applications
Christopher Frenchi
AI Research Engineer
Nish Tahir
Principal Software Engineer

Speech-to-text (STT) is an essential component for creating voice-powered experiences that delight users. A subset of automatic speech recognition (ASR), STT algorithms enable you to apply text-based natural language processing (NLP) techniques to a user’s intentions. This makes speech-to-text perfect for use cases like:
- Generating video captions
- Transcribing meetings
- Converting voice to plain text for analysis
However, the speech-to-text landscape has become increasingly competitive in a short amount of time. Just like with evaluating large language models (LLMs), AI practitioners are under pressure to test and benchmark more and more speech-to-text models to find which best fits their applications.
How to pick the best speech-to-text model
When choosing a speech-to-text model, it’s essential to consider factors such as:
- Word error rate (WER): How accurate a model is at transcription, based on quantifying how many mistakes it makes when transcribing an audio clip.
- Words per minute (WPM): How fast a model processes text, a high-impact metric if you plan to process multiple or extended audio clips.
- Cost: how much the model costs, if applicable (paid services typically price their offering per minute of audio).
- Multilingual support: How many languages the model or service supports.
- Streaming: How well a model performs for use cases that demand near real-time transcription, such as enabling sentiment analysis in customer service environments like contact centers.
The importance of these factors will differ depending on your scenario. For example, real-time voice applications may favor higher WPM at the cost of WER or even literal cost. Likewise, multilingual support may be the most critical factor when developing a voice solution for broad or international audiences.
Moreover, factors beyond those mentioned above could become priorities based on what you need. Diarization, the ability to identify different voices and then segment the transcript by speaker, might be mission-critical in environments like board rooms and law offices.
Methodology: How we chose and tested 10 speech-to-text models
We started by selecting high-performing and popular models listed in the Artificial Analysis Speech to Text AI Model & Provider Leaderboard. We then chose several models from large cloud vendors, as these may already be available via your cloud provider. OpenAI’s Whisper was the only open-source model we tested, though half of our final test list represented Whisper-based models:
- assemblyai-universal-2
- azure-ai-speech
- deepgram-nova-2
- gladia
- groq-distil-whisper
- groq-whisper-large-v3
- groq-whisper-large-v3-turbo
- openai-whisper-large-v2
- speechmatics
- whisper-large-v3-local
We tested the models against voice samples broken down by duration, language, and number of speakers present in the clips. This formed rough buckets of scenarios users will likely encounter in the wild.
Short-form clips, roughly 30 seconds of audio (single speaker):
- Native English speakers
- Non-native or accented English speakers
- Non-English speakers (French)
Medium clips, roughly 4–5 minutes of audio:
- English, one speaker (~4 minutes)
- English, two speakers (~5 minutes)
Long-form content, approximately 40 minutes of audio (preprocessing was done on the audio before sending to account for file limits):
- Panel discussions featuring multiple speakers
Audio clips included a small sample from the Facebook Voxpopuli dataset, an extensive collection of validated transcripts across 18 languages and non-native speech data for short audio. Though most of our sample clips were English, we included clips with various accents to simulate real-world conversations. We utilized medium-length content from our very own TELUS Digital YouTube channel, and long-form audio came from a Microsoft Research Forum panel discussion.
We scored each speech-to-text model based on WER and WPM metrics, as described earlier. We calculated WER using the jiwer python library using wer_standardize with `RemovePunctuation` enabled. As for WPM, we took the words in the transcript and divided them by the latency. Last, we evaluated whisper-large-v3-local on an Apple MacBook Pro running a M3 Max chip, 36 GB of memory, and macOS Sequoia 15.1.
Word error rate (lower is better)
Overall, assemblyai-universal-2 appeared to be the best speech-to-text model we tested. It performed the most consistently across our scenarios and exhibited the lowest cumulative WER score, as shown in the graphic below.
However, it’s worth noting that our clips contained instances of spoken numbers, which were transcribed differently by different models. This caused some deviation from the reference transcriptions and may have introduced some inconsistency with the WER calculation. The excerpt below illustrates this.

So, whereas the human transcriber of our reference dataset chose to write out “eleven point one percent next year is twenty-seven million,” most SST model training solves this problem differently. As we see above, “11.1% next year is 27 million” and “11.1% next year is 27,000,000” are both correct interpretations of the audio, but they're technically wrong because they don't match the source data. In reality, all the SST models performed accurately here.
Words per minute (higher is better)
In terms of transcribing audio the fastest, groq-distil-whisper was the best speech-to-text model we tested. It handled all of our different audio durations for transcription, but with one important caveat: groq-distil-whisper is English only.
It's also worth mentioning here that the top three speech-to-text models with the fastest WPM performance all came from Groq.
Cost
Most of the speech-to-text services we tested offered very competitive pricing, either billing per hour or minute of audio transcribed. groq-distil-whisper currently offers the most competitive pricing with groq-whisper-large-v3 and groq-whisper-large-v3-turbo coming in closely behind, all offered by Groq.
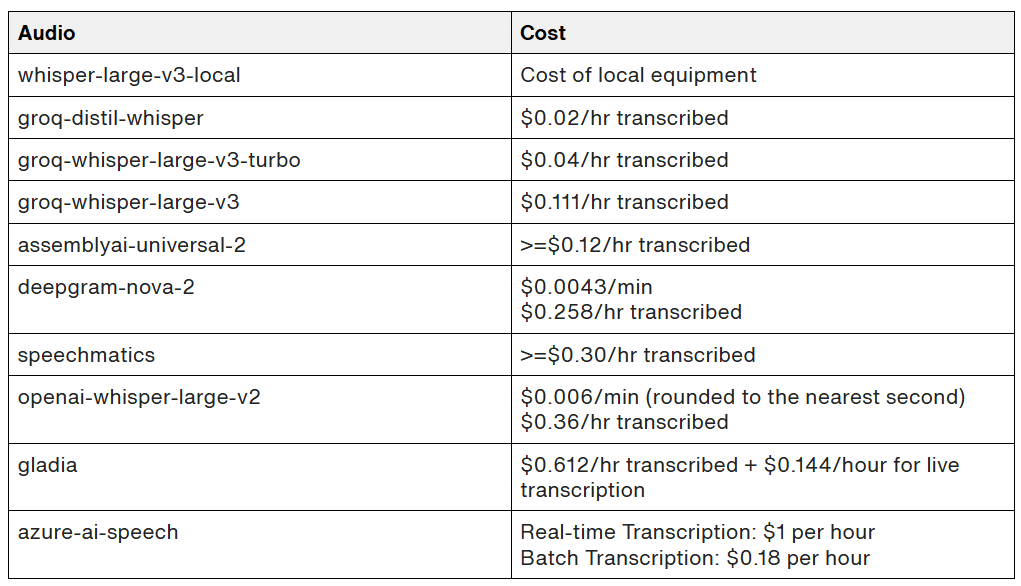
Pricing accurate as of published date. Important note: azure-ai-speech requires batch processing for larger audio files, which requires moving the audio file to a cloud storage bucket before processing, potentially resulting in additional costs. Gladia requires uploading the file to their servers and then performing transcription on the audio_url generated.
Multilingual support
During our tests using a short French clip about 30 seconds long, whisper-large-v3-local performed the best. Outside of running locally, there was a tie between the lowest WER across four models:
- assemblyai-universal-2
- speechmatics
- groq-whisper-large-v3
- groq-whisper-large-v3-turbo
Note that all models tested allow for multi-language support (with the exception of groq-distil-whisper), but depending on your use case and language needed, it’s a good idea to check the API documentation to see the specific services available for language support.
Hallucinations
An important callout when doing STT transcription is that as generative AI integrates more into voice-powered workflows, the chance of AI hallucinations increases. While all models we tested performed well, instances will occur where transcription won’t match what’s expected (i.e., some models may produce words or statements that are not there). Furthermore, the potential consequences will vary based on industry and application (e.g., see this study on speech-to-text hallucinations in healthcare).
Accelerate your development of speech-to-text applications
We’re excited that the speech-to-text landscape is better and more diverse than ever. Based on our testing, we found assemblyai-universal-2 to be the best model in terms of word error rate, but all the models performed very well. groq-distil-whisper won out in terms of cost and speed, but is limited to English.
Factoring in WER, WPM, cost, multilingual support and streaming capabilities, we think groq-whisper-large-v3-turbo is the overall best speech-to-text model available right now. However, best is relative. Ultimately, you should select a speech-to-text model based on your priorities and use case.
If you need help choosing the best speech-to-text models for your apps, we can help you:
- Optimize your speech-to-text models for specific tasks (e.g., transcription)
- Test different models to find the best application-model fit
- Stream content into your app to activate voice-powered experiences
And beyond. Learn more about our approach to developing AI Products & Solutions as well as Intelligent Conversational AI Solutions.