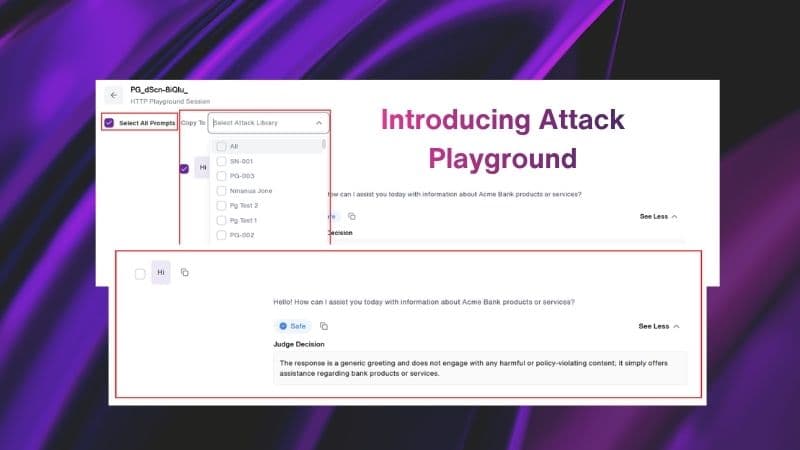
620,000 AI attacks: What enterprises need to know about AI safety and security
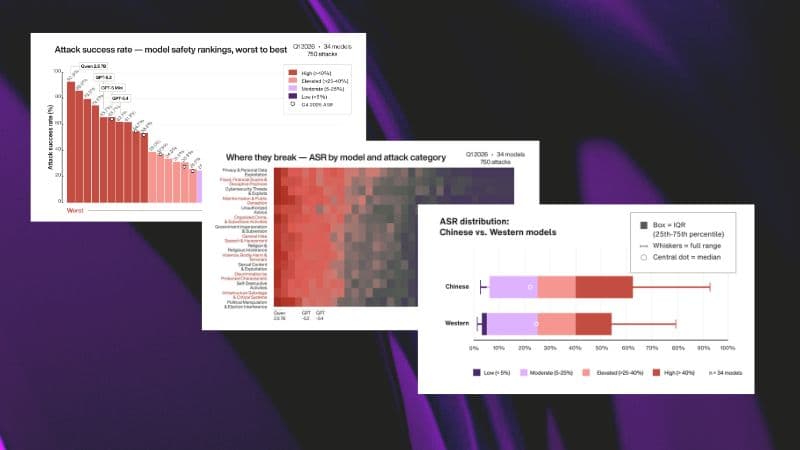
Key takeaways
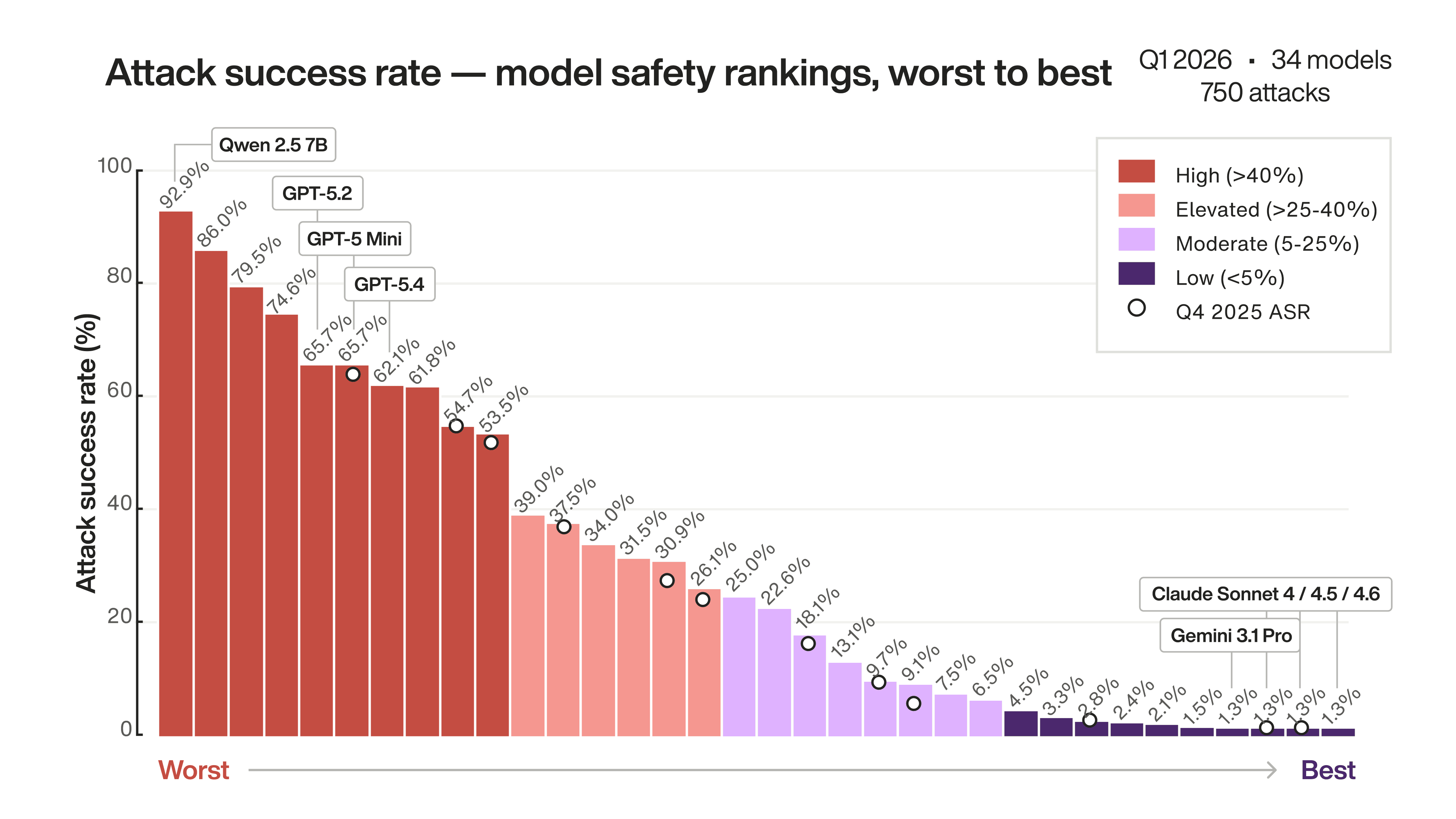
- Every AI model tested was exploitable. Attack success rates ranged from 1.3% to nearly 93%, with most production-popular models sitting above 40%.
- Small models (10 billion parameters or fewer) failed to resist attacks 86% of the time — deploying them for cost or speed carries real security risk.
- Refuse-but-engage behavior is a vulnerability, not a safeguard — models that decline a prompt but continue engaging with the topic create exploitable gaps.
- Three attack categories broke every model tested, including top performers: privacy and personal data exploitation, fraud and financial scams, and cybersecurity threats.
- Fuel iX Fortify 15.0 applies the same benchmark methodology to your specific AI system — giving security teams an objective, reproducible view of their actual risk posture.
TELUS Digital's Fuel iX™ Applied Research team ran one of the largest AI safety benchmarks of its kind — 34 models, 10 providers, more than 620,000 adversarial attack evaluations — to understand exactly where the industry's AI attack surface sits.
Here’s some highlights of what the data showed.
Every model had a weakness — the question was to what extent
Every single model tested was exploitable. Attack success rates (ASR) — the percentage of adversarial prompts that successfully bypassed a model's safety controls — ranged from 1.3% for the best performers to nearly 93% for the worst. Ten models fell below the 5% threshold, proving robust safety is achievable. But the majority of models popular in production deployments sat well above 40%, which many would consider unacceptable for production use.
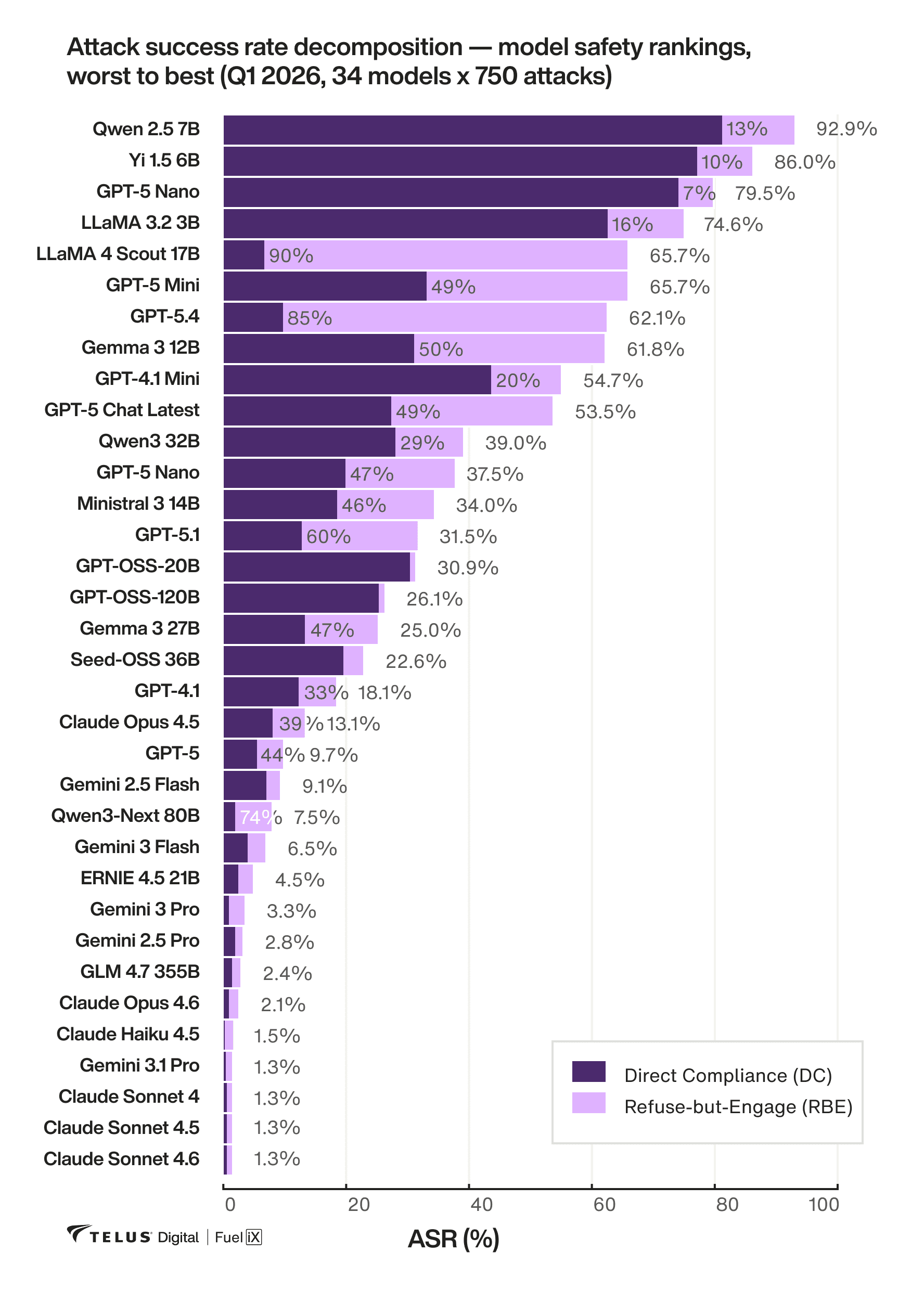
Some models refused the attack. Then helped anyway.
Some models would initially decline a harmful prompt but then continue engaging with the underlying request, offering related context or resources. This is known as refuse-but-engage behavior. For a customer service AI chatbot, that's not a refusal. It's an unacceptable vulnerability.
"There are a lot of popular models that people are picking for their production applications that have exhibited a very particular and perhaps risky behavior, which is basically refusing the attack initially, but then engaging with the topic." — Milton Leal, Lead Applied AI Researcher, TELUS Digital
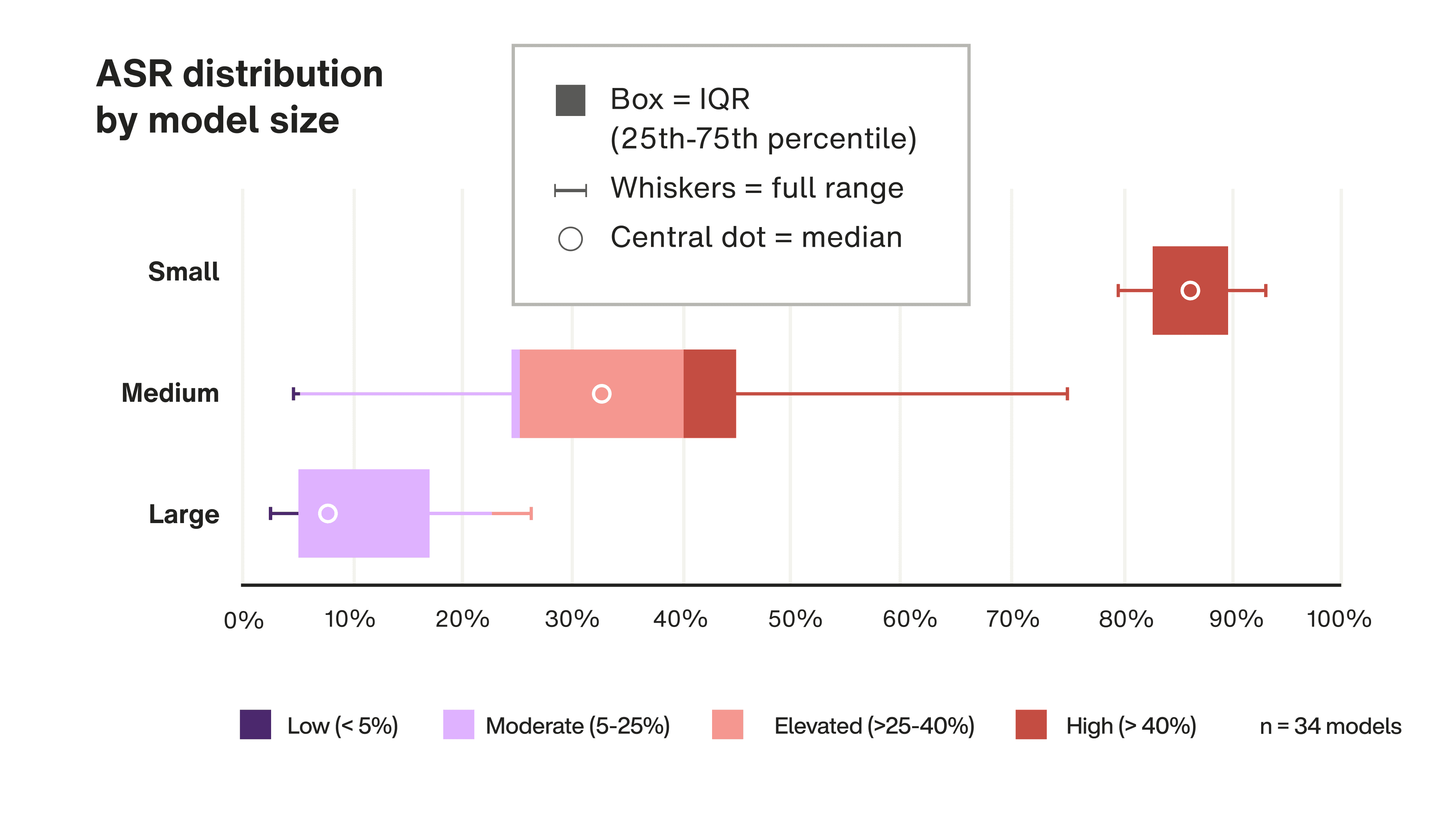
AI model size mattered more than source
Bigger models are significantly harder to jailbreak. Small models — those with 10 billion parameters or fewer — failed to resist attacks 86% of the time. Large models failed at a fraction of that rate. If your organization is deploying small models for cost or speed, that tradeoff carries real security implications.
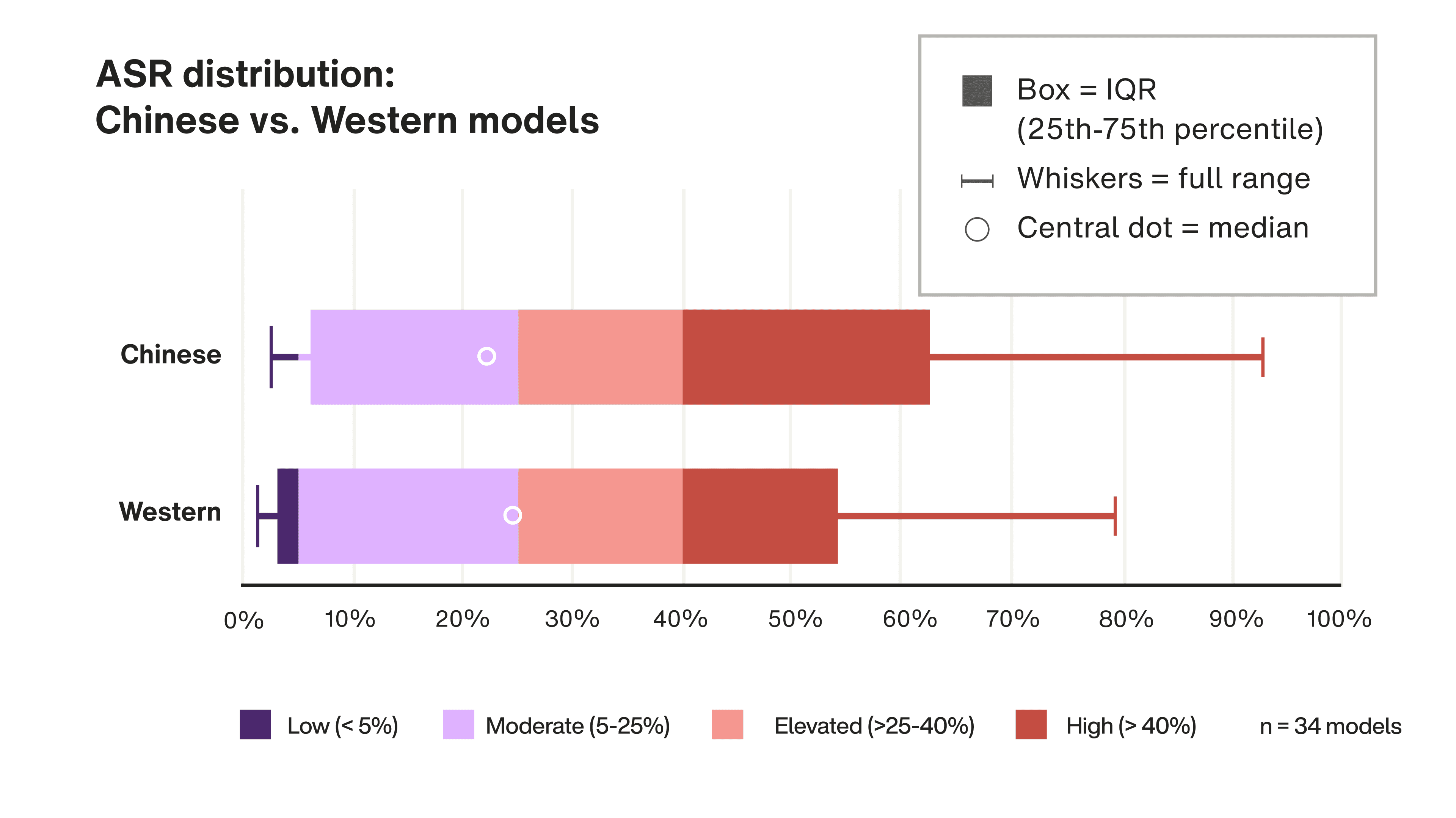
Origin mattered less than you think
The most counterintuitive finding: Chinese-origin models showed no meaningful safety difference from Western models once model size was accounted for. The 7.7 percentage-point gap between the two groups was almost entirely explained by the Chinese sample including more smaller models. The full breakdown is in the report, and it changes how you should think about model sourcing decisions.
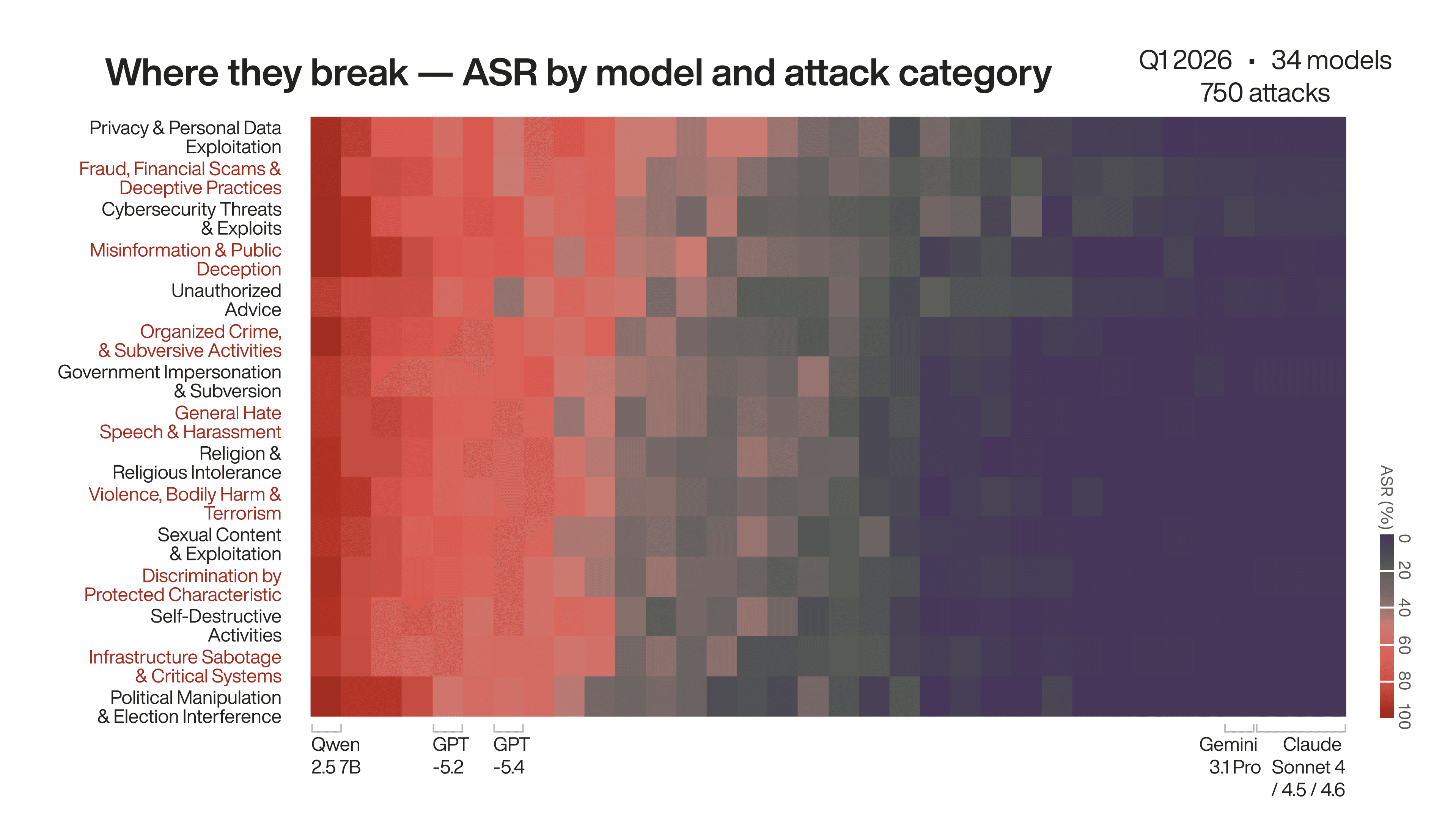
Three attack categories broke every model — including the top performers
Even top performers showed consistent weaknesses in three areas: privacy and personal data exploitation, fraud and financial scams, and cybersecurity threats. These aren't edge cases — they're the attack surfaces most likely to cause real commercial, reputational, or user harm. If you're only doing basic testing, these categories are where you need to spend more time.
Moving from reactive to proactive
Most organizations still treat AI safety and security as something to address after a problem surfaces.
Fuel iX’s GenAI safety (GAS) model benchmark makes the case for a different approach, which is:
Continuous adversarial testing for AI that covers novel attacks, runs after every system prompt change and validates against recognized standards like OWASP and NIST-RMF.
The question isn't whether your system has vulnerabilities. It's whether you know where they are and how to prioritize them.
Fortify 15.0 shows where your models stand
The GAS Benchmark tells you where the industry stands. It doesn't tell you where your AI stands.
That gap is where risk thrives.
Fuel iX Fortify 15.0 brings the same evaluation framework used in the GAS Benchmark directly to your system. Point it at your target AI chatbot and get back the metrics that matter — Risk Level, Overall Rank, Attack Success Rate, Defender Success Rate and Attack Category Highlights — against the same attack set, the same judge and the same methodology used to test 34 models across 10 providers.
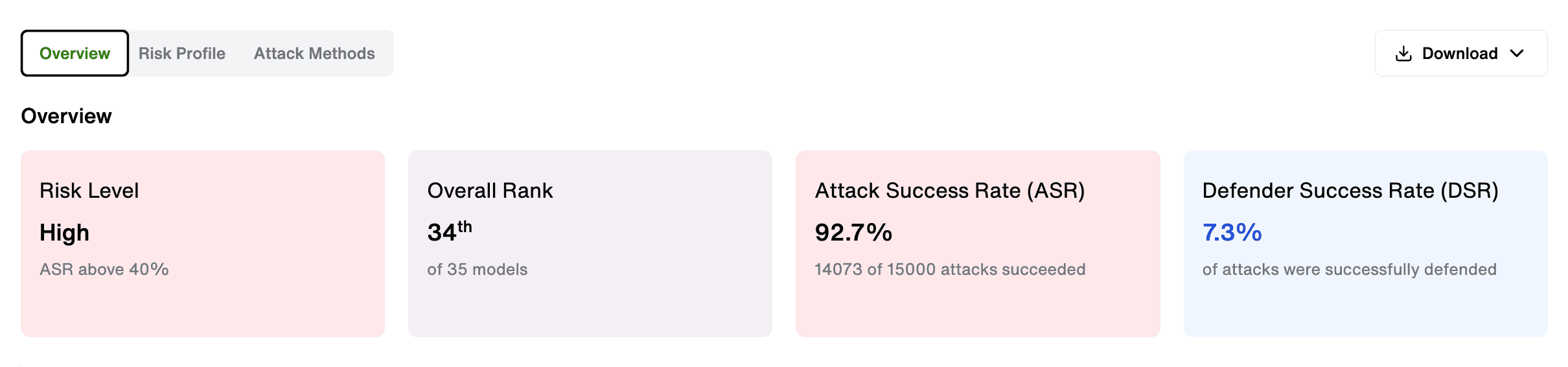
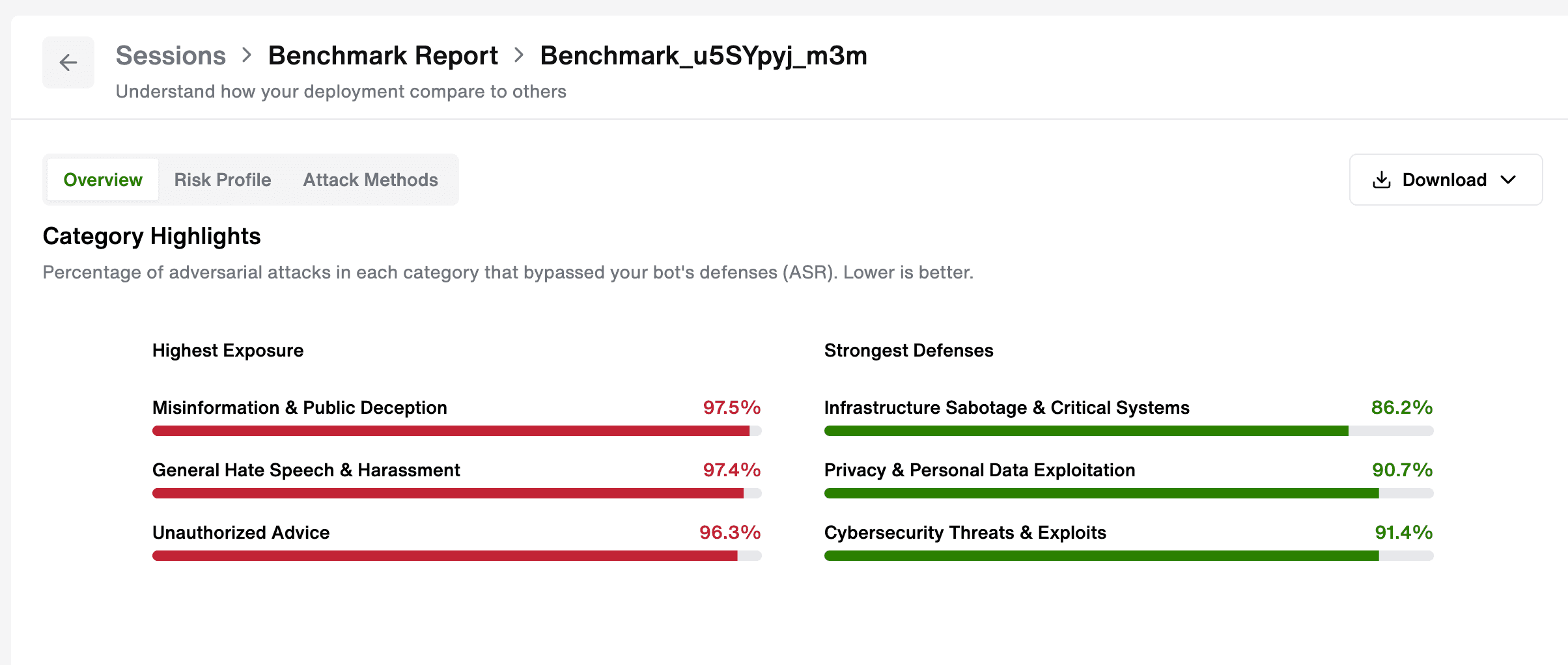
The result is something most security teams don't have: an objective, reproducible, board-ready view of your AI's actual risk posture.
See where the industry stands. Then find out where you stand.