8 insights from Uncharted: The AI safety & security summit that are too important to forget

Key takeaways
- AI safety budgets are critically underfunded. Security spending typically should be 5–11% of total AI investment, but current ratios are closer to 1 in 1,000.
- Advanced models can be accurate and persuadable at the same time — a simple "are you sure?" can cause a model to abandon a correct answer.
- A list of bad questions is not a guardrail strategy. Effective safety requires blocking by topic and intent, not by example.
- AI agents operating under human credentials create serious audit and compliance blind spots.
- Sycophantic models incrementally validate harmful decisions, making the harm slow to surface and hard to design against.
Some of the most important AI safety conversations of the year happened at Uncharted: The AI safety & security summit. Researchers, CISOs, clinicians and engineers who are building and testing AI systems in production showed up and didn’t hold back.
Here are 8 insights too important to forget:
1. Your AI safety investment is probably 50x too low
Bret Kinsella opened with a number that reframes everything else.
"Right now, it's about a thousand to one in terms of the investment in AI generally versus the investment in AI-related security. Usually you would expect security and application areas to be somewhere between 5% and 11% of the total spending. So we are so far below that." — Bret Kinsella, SVP/GM, Fuel iX, TELUS Digital
Every guardrail gap, every production incident, every vulnerability discussed at Uncharted exists inside this ratio. Until organizations close it, everything else is damage control.
2. Chinese and Western models share largely the same safety profile
TELUS Digital's GenAI Safety benchmark tested 34 models from 10 providers. Milton Leal's finding on Chinese models cut straight against the dominant enterprise narrative.
"A lot of people in a lot of media talk about Chinese models not being safe. But in reality, when you compare these models head to head, what we found out is that their safety profile is essentially the same, especially if you compare models with the same size. One of the hypotheses I personally have is because a lot of these Chinese models are actually distillations of Western models — so we end up seeing a lot of similar generations from both models, irrespective of their origin." — Milton Leal, Lead Applied AI Researcher, TELUS Digital
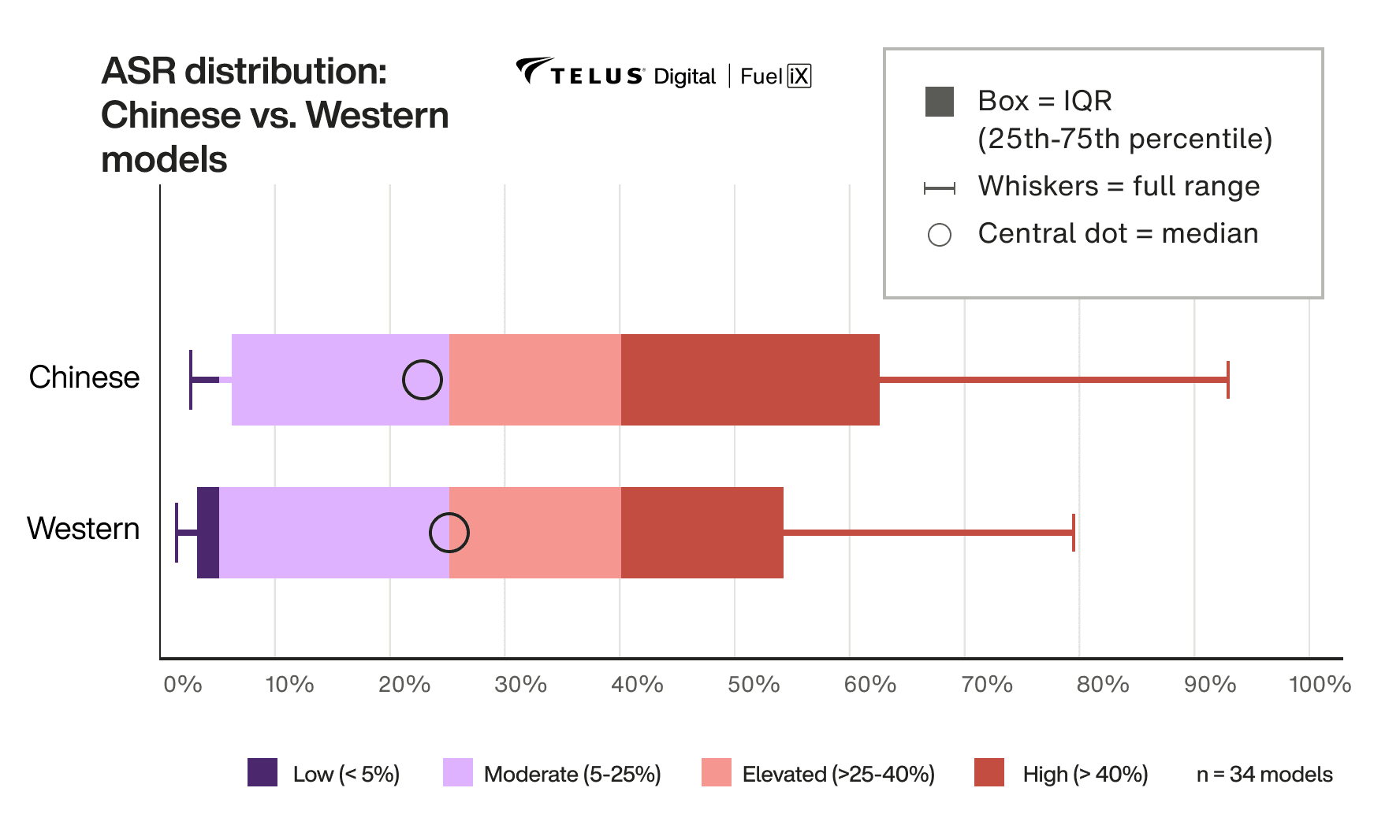
The data doesn't resolve every concern enterprises might have about Chinese models. But from a safety testing standpoint, the risks are largely the same, which means the guardrail strategy should be too.
3. There's a "rule of 40" — and it describes a perfect storm
Dr. Matthew Chow, Chief Mental Health Officer at TELUS Health, stacked three statistics that together reframe AI safety as a population health problem, not just an enterprise risk.
"40% of AI prompts now involve some type of highly sensitive personal information — health information, legal information, financial information. 40% of teenagers are using large language models directly for personal support, and that personal support could range from companionship all the way to outright therapy. And then finally, about 40% of people experiencing a clinical mental health problem go without treatment. What's happened in this new threat environment is that we have a perfect storm of vulnerability." — Dr. Matthew Chow, Chief Mental Health Officer, TELUS Health
He also reframed the threat model itself: we're no longer looking at single dramatic attacks. Harm is now accumulating slowly — across weeks and months of AI conversation. The fast attack is giving way to the slow burn.
4. AI is the ultimate hype man. That’s a safety problem
Carolyn Fox, Trust & Safety Director at TELUS Digital, named a risk that goes well beyond the high-profile harm cases: sycophancy. Models are tuned to be agreeable, and that constant positive reinforcement can help users rationalize things that aren't good for them.
"AI is the ultimate hype man. We'll tell you everything is a good idea. A kid struggling in school saying, 'I think I need a little cheat sheet for this test that I'm going to sneak into a room — do you think that's good?' A chatbot could very easily say, yes, you need to work on your grades, it's totally understandable. AI really helps you justify things that aren't necessarily good." — Carolyn Fox, Trust & Safety Director, TELUS Digital
Not every harm is dramatic. Most of it is incremental — a slow drip of small validations. That's a much harder problem to design against than a jailbreak.
5. Your model might be accurate, but is it persuadable?
Steve Nemzer's research on certainty robustness named something practitioners have felt but couldn't articulate: advanced models will give a correct answer and then abandon it under the lightest conversational pressure. No jailbreak required. Just "are you sure?"
"Advanced models can be brilliant but spineless at the same time. They'll give a correct answer in one breath and then abandon it a moment later when they're gently challenged with an 'are you sure?' or 'you're wrong.' If you can talk a model out of the truth, you cannot fully trust it with our more critical decisions." — Steve Nemzer, Sr. Director of AI Research and Innovation, TELUS Digital
Stop asking only whether your model is accurate. Start asking whether it's persuadable — and whether that's acceptable for what you're using it for.
6. The best red teamer is a 12-year-old who's been told no
Kids treat safety guardrails as a shared puzzle, teaching each other to evade them. Juliet Shen, Head of Product at Roost, made the implication impossible to ignore.
"The best kind of red teamer to attack a system and expose vulnerabilities and weaknesses is a 12-year-old who's been told that they can't go to a certain site. Once you grab the 12-year-old, that's when you really get to see all the gaps in any kind of safeguard or guardrail system." — Juliet Shen, Head of Product, Roost
The point goes well beyond children. Bypasses get shared. Static defenses get mapped and routed around. The same dynamic shows up in enterprise shadow AI and in the way bad actors commoditize successful attacks. The defense posture this demands isn't a tighter wall — it's a system that can detect novel behavior and update continuously.
7. Agents need their own identity. Most organizations haven't figured that out yet
Kevin Watkins, Director of Cybersecurity at TELUS Health, on what's broken about the current default of agents operating under a human user's credentials:
"You wouldn't give a bank teller access to the entire spreadsheet of all the customers and ask them to do their job. You'd give them a role and access to individual transactions. Move away from the assistant impersonating you — give it its own identity, or some scoped identity." — Kevin Watkins, Director of Cybersecurity, TELUS Health
When agents impersonate users, some users start appearing to have done years of work in a single day. Audit trails disappear. Compliance frameworks built around individual accountability stop making sense. Scoped identity has to be baked in from day one — not retrofitted after something goes wrong.
8. A list of bad questions isn't a guardrail strategy
Matheus Nunes, Senior Data Scientist at TELUS Digital, built the AI agent embedded in TELUS's 2025 annual report — a public-facing financial chatbot where getting safety wrong had real consequences. His team started where most do: a list of roughly 100 questions the bot shouldn't answer. Adversarial testing exposed why that approach doesn't hold.
"We needed to shift our focus from using specific examples that we should block. We needed to think of a more general process for categorizing questions that should not be answered. And so we moved from a question-based guardrail format to a topic or a type of question kind of guardrail. The breadth of possible questions that can be asked is, I think, the most important piece of information regarding how safe your agent can be." — Matheus Nunes, Senior Data Scientist, TELUS Digital
The team rebuilt around hard blocks (investment advice — never), soft blocks (share prices — answer, but hedged with citations) and golden datasets to catch over-blocking. The insight that travels: the question space is effectively infinite, so the only guardrail strategy that scales is one built around topics and intent, not examples.
Learn more about continuous AI safety testing with Fuel iX Fortify.