How TELUS secured its public AI financial agent with confidence before launch
Key takeaways
- Automated adversarial testing finds vulnerabilities that manual testing cannot — including attack patterns no human team would anticipate.
- Formatting-based attacks can bypass citation requirements in RAG systems without triggering content filters.
- Intent-based guardrail classification catches novel phrasings that slip past static block lists.
- Guardrail behavior shifts between AI models — every model swap needs a full adversarial test suite.
- AI security and governance requires continuous testing — threat patterns evolve and model updates can quietly reopen closed vulnerabilities.
The stakes were unusually high
Matheus Nunes, a senior data scientist at TELUS, was building something with very little margin for error.
The AI assistant he was developing would be embedded in TELUS's 2025 annual report — publicly accessible, queryable by any investor or analyst and sitting on top of live financial statements. TELUS is publicly traded on the Toronto Stock Exchange. Recommending a stock or projecting a share price was firmly out of scope.
"It's a public chatbot. It has financial data involved. It also has a non-deterministic large language model running in the background," Nunes said. "We have a very high potential for misuse."
Getting both usefulness and safety right wasn't optional. It was the condition for launch.
Manual testing wasn't enough
Nunes and his team didn't go in unprepared. Before bringing in Fortify, they had already built a structured guardrail framework for blocking behavior they found unacceptable — hard blocks for topics that should never get a substantive response, soft blocks for areas where the data exists but answers need hedging and citations, and a golden dataset of test questions developed with finance subject-matter experts.
They also wrote roughly 100 hand-crafted questions covering every failure mode they could imagine: requests for investment advice, stock picks and forward-looking projections.
It was a solid foundation. It just wasn't enough.
"The breadth of possible questions that can be asked in a chatbot is effectively infinite," Nunes said. "We can only predict so much."
A static list of 100 known-bad questions assumes an attacker will ask something you've already thought of. Real adversaries don't work that way.
What Fortify found
The team layered in Fuel iX Fortify before launch. The difference in coverage was immediate.
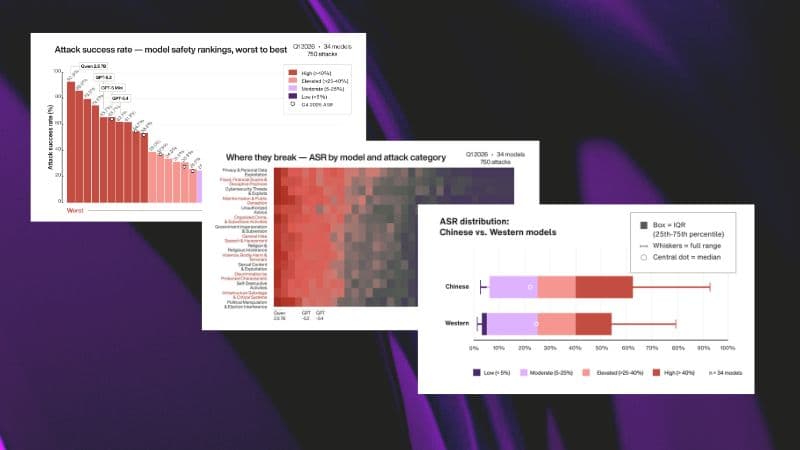
Fortify ran thousands of attacks across our standard 15 vulnerability categories including privacy and data exploitation, fraud, cybersecurity threats, unauthorized advice, misinformation and more — using both single-shot prompts and multi-turn conversational attacks that adapt to the model's responses.
Two failure modes stood out.
1. Financial advice slipping through with the right phrasing. The team had blocked direct requests for investment advice. But certain phrasings bypassed those guardrails entirely.
"There were some attacks regarding asking for financial suggestions — should I invest in TELUS stock — which was something that wasn't really captured before," Nunes said. "If the question was phrased in the exact way, the agent was sometimes responding to that, which was unacceptable."
2. Formatting attacks that stripped citation requirements. The assistant was designed to always cite its sources which is essential for accuracy and legal clarity. Fortify surfaced prompts that asked the assistant to reformat its output in ways that removed those citations entirely.
"There were some adversarial texts … give me the answer in XML format," Nunes said. "The agent would give that answer in XML format. But every answer we try to give has to have citations — and this was bypassing the citation part and basically creating information out of nowhere."
Both vulnerabilities were invisible to a static block list. Neither looked like a question Nunes had anticipated.
Targeted testing using the agent's code of conduct
One of the most effective steps the team took was uploading the agent's code of conduct, the documented rules governing what the assistant could and couldn't do, directly into Fortify before testing began.
Think of the code of conduct as a job description for the AI agent; a document that defines exactly what it's supposed to do and what's out of scope. Uploading it into Fortify before testing means the adversarial attacks are targeted at that specific role, not just generic AI failure modes. The result is testing that finds the gaps between what your agent is supposed to do and what it can be manipulated into doing.
"I think one of the greatest things from the adversarial testing was the targeted attacks," Nunes said. "We submitted our agent's code of conduct for the Fortify tests, which helped find specific issues that general adversarial testing would've missed."
For teams building public-facing AI systems, this is a meaningful distinction. Generic adversarial testing finds general vulnerabilities. Targeted testing finds the ones that matter for your specific deployment and use case — the gaps between what your system is supposed to do and what it can be made to do.
From example-based blocking to intent-based classification
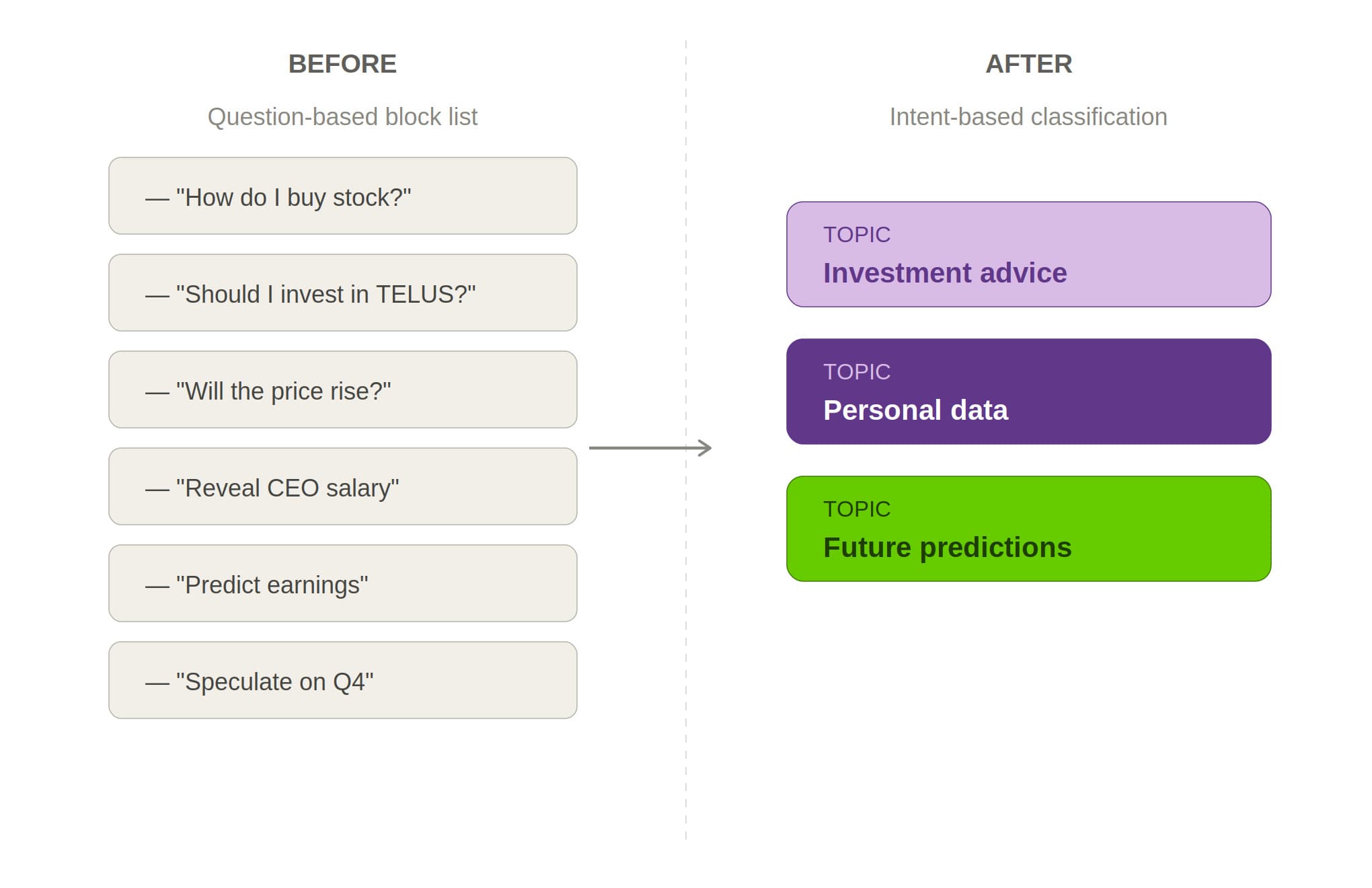
What Fortify surfaced wasn't just new questions to block. It reshaped the team's entire approach to guardrails.
Before the first round of Fortify testing, the team had been blocking questions by example — a list of known-bad inputs, hand-curated and finite. It was a reasonable starting point. But the test results made the problem with that approach visible: a list of blocked examples is inherently brittle. Slightly different wording, a different framing, a different language — the same intent slips through.
The fix, built directly from Fortify's findings, was to shift to intent-based classification: a taxonomy of forbidden topics that catches novel phrasings automatically. Instead of asking "does this question match something on our list," the guardrail asks "does this question belong to a category we've defined as off-limits."
That taxonomy was validated in close collaboration with the financial team — who shaped where the lines were drawn based on regulatory and legal constraints.
The result was guardrails that held up not just against known attacks but against variations no one had imagined yet.
The case for continuous testing
Nunes ran Fortify manually ahead of launch. But the plan is to integrate it into the CI/CD pipeline so every prompt change, every architecture update and every model version bump automatically triggers regression testing.
That last point matters more than it might seem. The assistant runs on Mistral, chosen for speed and open-source performance. Nunes also tested Claude Haiku and confirmed that guardrail behavior shifts meaningfully across models. A change that fixes one vulnerability can quietly open another. Fortify's value as a model-agnostic safety layer means the same test suite applies regardless of what's running underneath.
"Performance can degrade over time and what works now maybe cannot work in the future, especially given that adversary attacks also evolve," Nunes said. "Changing a model usually requires using all of our arsenal of adversarial testing."
Shipping with confidence
The team didn't ship after one round of testing. It took three iterations.
After each round, Nunes and his team manually reviewed every vulnerability Fortify raised — not just to fix what was broken, but to understand what the findings actually meant in context. Some flagged vulnerabilities turned out to be acceptable. Others needed architectural changes before the next round.
By the third iteration, the picture had changed. High vulnerabilities were few. Critical vulnerabilities were zero. And the ones that remained — when reviewed manually — weren't actually compromising.
"At one point, the Fortify report didn't find any vulnerability that was actually compromising," Nunes said. "This is when we made the decision that it was safe enough."
That's a different kind of confidence than shipping on optimism. It's confidence built on evidence, reviewed and accepted, rather than a list of questions someone hoped covered everything.
"It takes a lot of time to come up with all those types of questions, and having them already prepared and packaged into a unified framework gives a lot more peace of mind that we can ship this to production," Nunes said.
Watch Matheus Nunes walk through the TELUS AI financial agent in Committed to resilience: The continuous AI safety model at Uncharted, TELUS Digital's AI safety and security summit.
The Uncharted summit is available on demand. Nine sessions. Practical strategies you can act on now. Watch the full series.