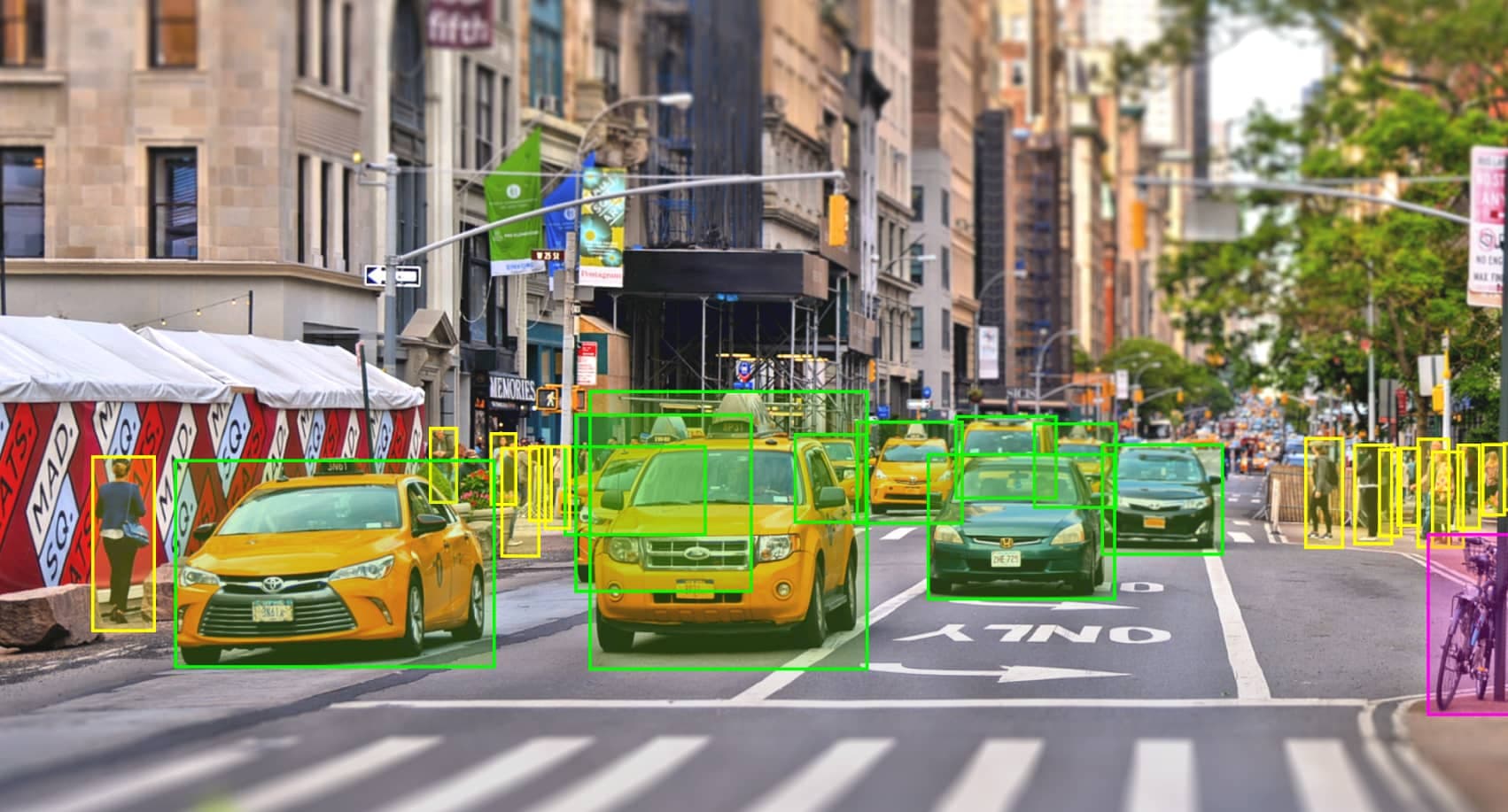
Training data
What is training data?
Training data is a collection of labeled information that is used to build a machine learning (ML) model. It usually consists of annotated text, images, video or audio. Through training data, an artificial intelligence model learns to perform its tasks at a high level of accuracy.
In other words, training data is the textbook that will teach a model to do its assigned task. Think of the algorithm as a student and the training dataset as a textbook filled with example problems. The more the algorithm “studies”, the better it does in the final test, which is real world application.
Most training data contains input information and corresponding annotations. These annotations, also called tags or labels, contain relevant metadata that helps models make more accurate predictions.
To build a ML model, three types of training data are needed, each of which performs a different role:
- Training data: Used to help a ML model make predictions. It’s the largest part of a dataset, forming at least 70-80% of the total data used to build a model. This data is used exhaustively across multiple training cycles to improve the accuracy of an algorithm.
- Validation data: Primarily used to determine whether a model can correctly identify new data or if it’s “overfitting” to the original dataset — when the model memorizes the “noise” in the training set, making it unable to perform the task it was intended for. Validation enables data scientists to adjust hyperparameters and improve the model’s accuracy.
- Testing data: Used after both training and validation, it aims to test the accuracy of a final model against its targets. It also provides further confirmation that the model isn’t overfitting to the training and validation data.
Benefits of training data
Training data is used to create ML models that are used in applications such as autonomous vehicles, chatbots, voice assistants, search engines and much more. The benefits of training data include:
- Making automation possible: Products and services that incorporate machine learning couldn’t exist without training data, and the amazing technological advances and efficiencies that have been made possible through ML would not be a reality today.
- Increased ML effectiveness: The success or failure of a ML model is defined by the cleanliness, relevance and quality of the data used. Just as a student with an outdated textbook is unlikely to achieve top marks, a model will only excel at its task if the data accurately reflects the real-world scenarios it was built for.
- Provides a competitive edge: High-quality, differentiated training data produces top-performing applications which can be a competitive advantage for businesses.