How do enterprises test AI safety and security? Five approaches and how to choose

Key takeaways
- AI systems are probabilistic. The same attack can fail nine times and succeed on the tenth.
- Manual red teaming surfaces novel vulnerabilities but doesn't scale. A four-minute system prompt change can take two days to manually retest.
- Automated red teaming provides coverage at scale but only works if the attack library stays current. Stale attacks measure how well a system passes its own exam.
- Mature AI security programs layer all five approaches, with feedback loops connecting testing, monitoring and compliance documentation.
AI deployment is accelerating faster than the security frameworks built to govern it. According to the World Economic Forum's Global Cybersecurity Outlook 2026, 87% of security leaders flagged AI-related vulnerabilities as the fastest-growing cyber risk, yet most organizations still lack continuous security assessments and clear accountability for their AI models, applications and agents.
The AI attack surface is expanding, and it behaves nothing like traditional, deterministic software. Security teams are now responsible for protecting probabilistic systems that can be manipulated through natural language alone — systems they may not fully understand yet.
TELUS Digital has built and secured AI models, applications and agents across industries, processing more than two trillion tokens in production. What we've learned is that there is no single playbook. But there are five approaches that most enterprise teams use, and each comes with real trade-offs.
Later in this post, we look at how Island Health put this into practice and what they learned about securing a public-facing AI system in a high-stakes environment.
Why securing AI is different
Traditional security frameworks were built for deterministic systems. Define the inputs, predict the outputs, test the edges. AI breaks that model entirely.
GenAI applications are context-dependent. The same model can behave differently depending on the system prompt, the grounding data it's given or the order in which a conversation unfolds. A few lines of system prompt can introduce new vulnerabilities, without any change to the underlying model.
The threat vectors are different, too. Attackers exploit language, not code. When testing an AI system for vulnerabilities, security teams need to simulate attacks like prompt injection, jailbreaks and PII exfiltration — none of which appear on a traditional pen test checklist. Multi-turn manipulation is particularly difficult to catch: rather than a single malicious input, a multi-turn attack builds context over several exchanges, establishing a persona, shifting the framing and building apparent trust until the model's defenses are effectively off.
And unlike traditional software, AI vulnerabilities are probabilistic. The same attack might be blocked nine times and succeed on the tenth. A single test pass does not give you a reliable picture of your exposure.
This is the context in which AI red teaming and adversarial testing exist. Unlike penetration testing — a systematic, time-bound search for technical vulnerabilities in infrastructure — red teaming simulates real-world attacks over time, testing not just technology but how well defenders detect and respond. For AI systems, that distinction matters more than anywhere else. A one-time pen test identifies what's wrong with a static system. AI systems change constantly. A model update, a system prompt edit or a new tool integration can introduce new vulnerabilities overnight. Testing needs to be continuous, not periodic — and it needs to simulate the full range of language-based attacks, not just the ones on a fixed checklist.
All five approaches share a common purpose: identifying where your AI system's defenses need to improve. Governance defines what good looks like. Red teaming finds where you're falling short. Automated testing does it at a frequency that keeps pace with how fast your system changes. Runtime monitoring catches what testing missed. None of that information does anything until it feeds back into your guardrails — or in some cases, into your training data. The approaches aren't a progression. They're a feedback loop.
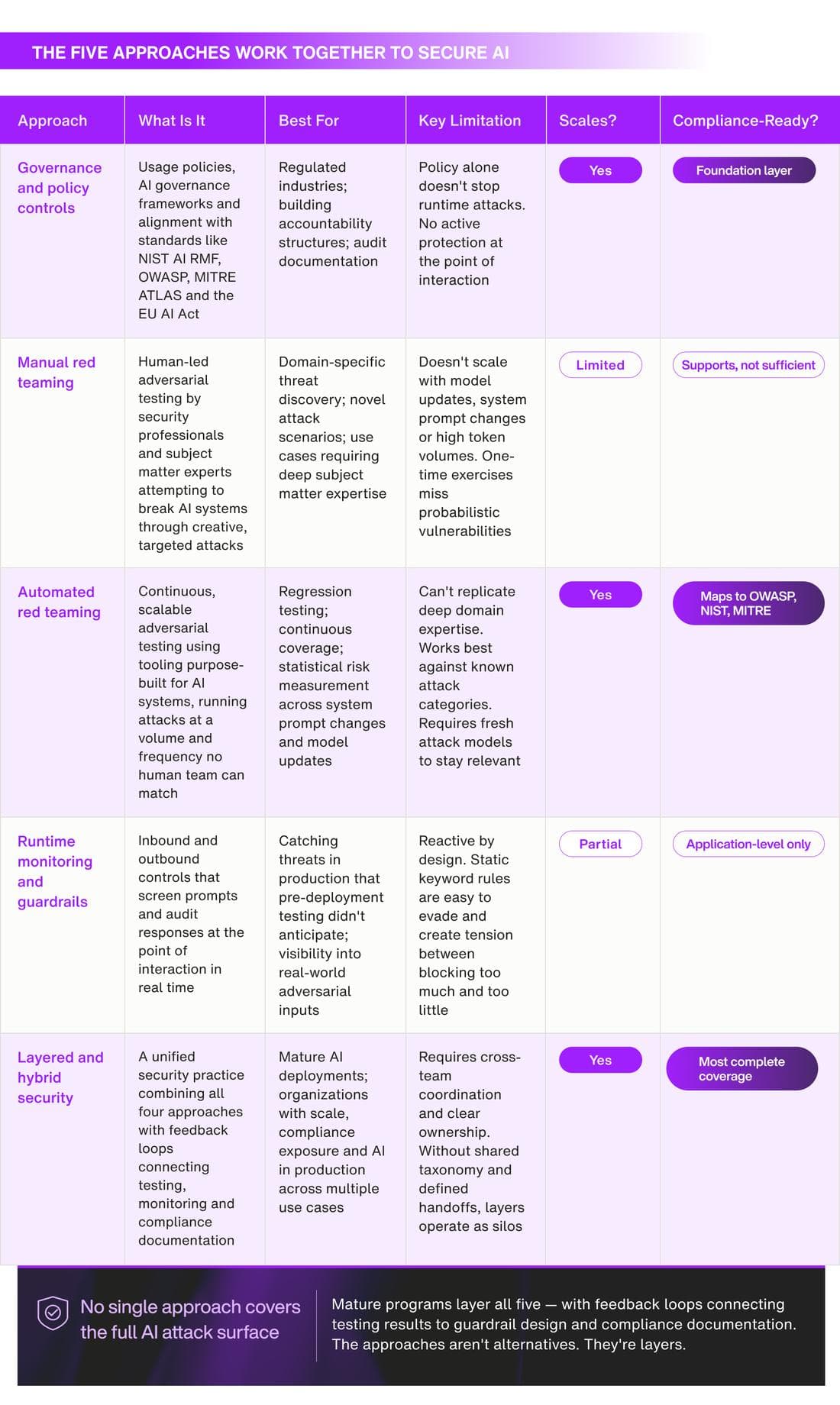
The five approaches enterprise teams use to secure AI
Governance and policy controls
Governance is the foundation. Usage policies, internal AI governance frameworks, alignment with standards like NIST AI RMF, OWASP, MITRE ATLAS and the EU AI Act. It defines what your AI systems should and shouldn't do, who is accountable and how compliance is documented.
Governance and policy controls matter in every industry. In banking, healthcare and government they are non-negotiable. Audit-ready documentation is a legal requirement, not just good practice.
Where it falls short: policy doesn't protect you at runtime. Governance and policy controls are inert without two things: identification of bad behavior and enforcement through mitigation or remediation. A well-written governance document has no mechanism to verify whether your deployed system is actually behaving the way it says it should.
That gap, between what a policy says and what a deployed system does, is where most governance programs break down. Without active testing, monitoring and mitigations connected to it, governance has no real teeth.
Manual red teaming
Human-led adversarial testing: offensive security professionals, subject matter experts and red teamers attempting to break an AI system through creative, targeted attacks. Purple teaming, which combines red team attack design with blue team remediation, is a more collaborative evolution of this approach.
Manual testing is strongest for creative, context-specific attacks that don't map to established vulnerability categories. Bringing in diverse voices — GRC teams, end users, security analysts and application owners — tends to surface vulnerabilities a more homogenous team would miss.
Where it falls short: it doesn't scale, and the math works against you faster than most teams expect. A team runs a manual red team exercise before launch — fifty attack scenarios, two days of testing, sign-off from security. Three weeks later, a developer updates the system prompt. That change takes four minutes. Re-running the full exercise takes two days, so it doesn't happen. The updated system goes to production untested.
And because AI vulnerabilities are probabilistic, running each attack once doesn't tell you much anyway. A vulnerability with even a low probability of triggering needs to be tested repeatedly across many variants to show up reliably. At human speed, that's not practical.
The result is a security posture that reflects how the system behaved at launch, not how it behaves today. For a GRC team responsible for documented compliance, that's not a testing problem. It's an audit exposure problem.
Island Health faced exactly this situation when launching Shay, their public-facing career advisor chatbot. Manual red teaming was producing error rates as high as 13% and couldn't keep pace with the system's development. See how they solved it.
Automated red teaming
Automated red teaming is continuous, scalable adversarial testing using tooling purpose-built for AI systems. Instead of a one-time exercise, automated red teaming runs attacks across a defined set of vulnerability categories at a volume and frequency no human team can match.
It's particularly valuable for regression testing, catching whether a system prompt change, a model update or a new tool integration has introduced new vulnerabilities. Running the same attack 20-plus times, across many variants, gives you a far more reliable signal than a single pass/fail test and a much clearer picture of where your real exposure lies.
Where it falls short: automated red teaming delivers coverage and reproducibility at scale but it can't replicate the creative, hypothesis-driven attacks that come from deep domain expertise. A skilled human red teamer working in a specific industry brings contextual knowledge that a broad-coverage attack model can't replicate.
Most automated attack models are built for a wide range of use cases, not for niche or highly specific domains. A healthcare compliance system, a financial advice tool or a legal research assistant each carries domain-specific risks that a general-purpose attack library may not fully cover. Teams that deploy automated testing passively, without actively maintaining and extending it with domain-specific attack categories, risk building guardrails that pass the test but miss the threats that matter most in their specific context.
The underlying research behind the attack model matters as much as the volume of tests. As new attack categories, methods, threat vectors and risk surfaces like agentic AI emerge, the attack model must evolve to cover them. A tool running yesterday's attacks against guardrails built for yesterday's threats isn't measuring real-world exposure. It's measuring how well the system learned to pass its own exam.
Runtime monitoring and guardrails
Controls that operate at the point of interaction: inbound guardrails that screen prompts before they reach the model, and outbound guardrails that audit responses before they reach users. For RAG-based systems, context-level scans can also detect indirect prompt injections and enforce data access boundaries before grounding content reaches the model.
Guardrails catch threats that pre-deployment testing doesn't anticipate. No test environment fully replicates the adversarial creativity of real production traffic. The first time a user tries a social engineering approach your red team never thought of, your guardrails are the last line of defense.
Where it falls short: guardrails are often reactive and brittle, and most teams don't realize how brittle until something gets through. The typical pattern looks like this: an AI assistant goes live, an incident occurs, a new rule gets added to block the specific input or topic that caused it. Another incident, another block. Six months later, the guardrail layer is a patchwork of specific rules built in response to specific failures, each one closing yesterday's gap while leaving tomorrow's open. A determined attacker doesn't need to break the guardrail. They just need to find an angle that the existing rules weren't written to catch.
Static keyword-based rules compound the problem. Block the word "medication," and you've also blocked a healthcare assistant from answering legitimate patient questions. Loosen the rule, and you've reopened the gap. That tension, between blocking too much and blocking too little, is a sign that the guardrail was built reactively rather than designed proactively. Guardrails built without testing data behind them are guesses. And in a probabilistic system, guesses have a known failure rate.
Layered and hybrid security
The most mature teams don't rely on any single approach. They layer governance, testing, automated red teaming and runtime monitoring into a unified security practice with clear feedback loops between them.
In a layered program, each approach strengthens the others. Testing results inform how guardrails are designed and updated. Monitoring surfaces new attack patterns that feed back into the test library. Governance validates that the whole operation aligns with regulatory standards and produces the documentation that proves it.
How to think about what your team needs
Most teams overestimate where their AI security program actually sits.
- Are you testing your AI systems before every production change or only before initial launch?
- Do your guardrails get tested against real attack scenarios, or do you assume they're working?
- Can you produce documented evidence of your AI security posture for a compliance audit today?
Where you land depends on three factors.
- Where you are in the AI development lifecycle. Early-stage deployments can start with governance, basic guardrails and targeted manual testing. As volume and complexity grow, the gaps in that approach become harder to ignore and the cost of an incident grows with them.
- Scale of AI in production. The more AI you have running in production, the more comprehensive your security program needs to be. Organizations processing large volumes of tokens across many use cases can't rely on governance and basic guardrails alone. At scale, probabilistic risks become near-certainties. A vulnerability that triggers rarely in a low-volume deployment will trigger regularly when millions of interactions are running through the same system. The exposure compounds with every new use case, every new model update and every new user population.
- Compliance and regulatory exposure. Enforceable AI security mandates are now in effect in the US and EU. The EU AI Act requires documented conformity assessments before deploying high-risk AI systems. NIST AI RMF sets expectations for continuous monitoring and accountability across the AI lifecycle. GDPR creates specific obligations around PII handling and data governance that extend to AI systems processing personal data. For teams in regulated industries, that means personal accountability for documented AI security posture, not just organizational compliance. Continuous, documented testing is no longer a best practice. It is an operational requirement.
Start with two questions. How much risk are you willing to accept, and what are the realistic consequences of getting this wrong? For organizations in regulated industries, the answer usually points in one direction: toward continuous, documented testing that produces evidence of your security posture before an auditor, a regulator or an incident forces the question.
If any of these gave you pause, that's the gap. The Island Health story below shows what closing it looks like in practice.
Island Health: AI security in a high-stakes environment
When Island Health launched Shay, their public-facing career advisor chatbot, they faced a problem that most healthcare teams recognize immediately. A chatbot that hallucinates medical advice or responds outside its guardrails isn't just a technical failure. It's a reputational and compliance risk.
Manual red teaming was slow, limited in scope and producing error rates as high as 13%. With Fortify as the automated testing layer, Island Health cut testing time by 97% and achieved a 99.6% success rate in identifying AI vulnerabilities.
Read more on how Island Health approached AI security and governance.




