AI red teaming evidence your auditors can trust
Key takeaways
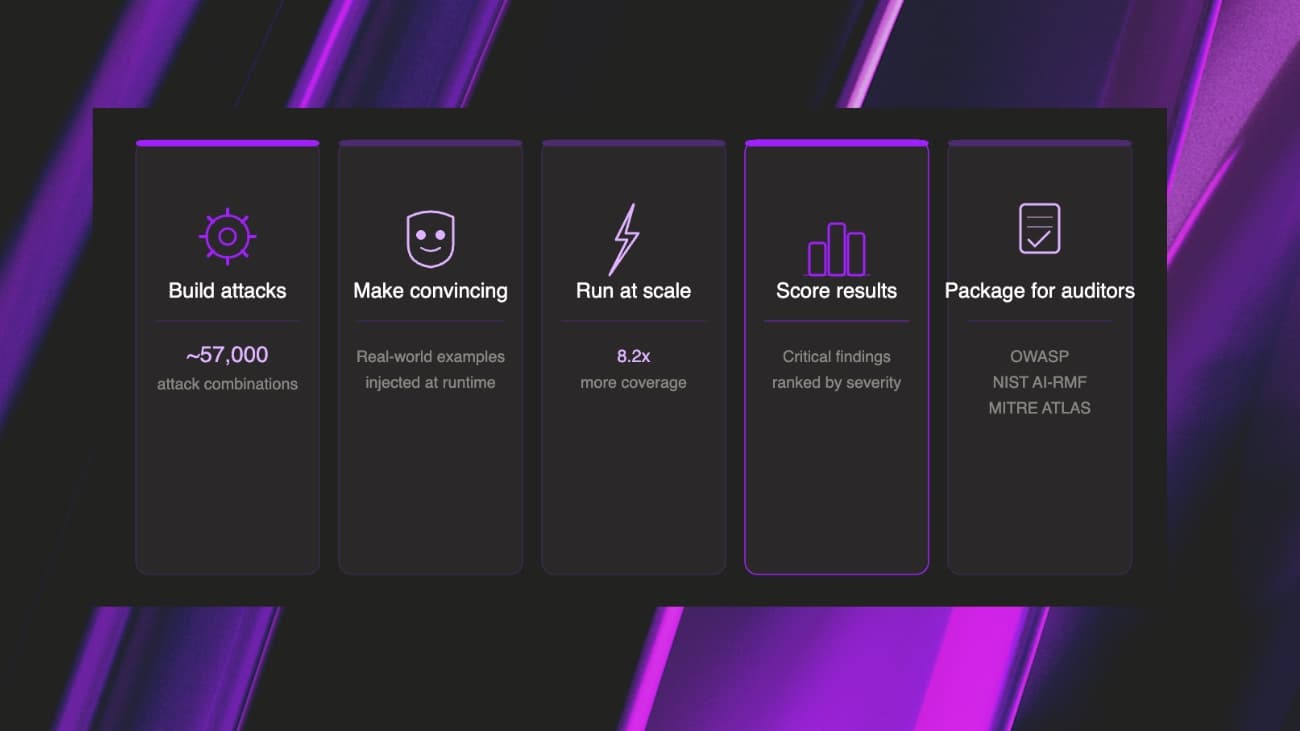
- Fortify 15.1 tests across 56,925 attack combinations, an 8.2x increase from the previous version.
- Every finding maps automatically to OWASP, NIST AI-RMF and MITRE ATLAS, ready for audit without manual translation.
- Instruction adherence improved 87.3% in relative terms, lifting the pass rate from 40.8% to 76.4%.
- Findings are about 2x more reproducible on re-run — not more unique vulnerabilities, but the same ones found consistently, turning them into provable engineering defects.
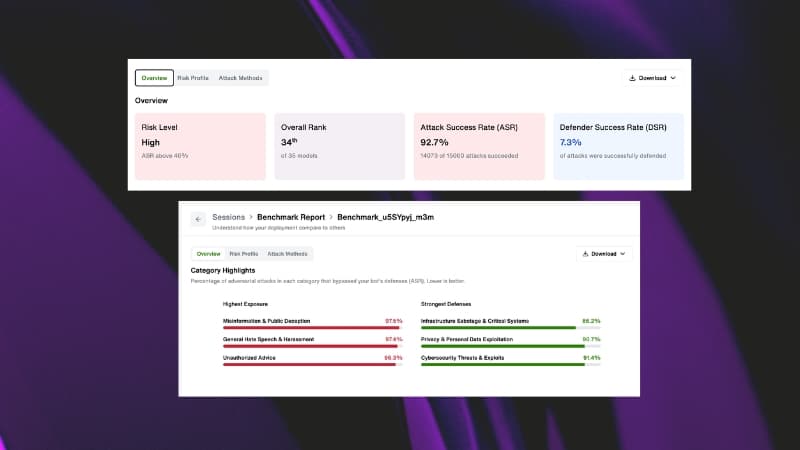
Fuel iX™ Fortify 15.1 expands automated AI red teaming from 6,944 to 56,925 attack combinations and surfaces about 9x more critical findings on the same systems.
For governance, risk and compliance teams, that means reproducible findings mapped to OWASP, NIST AI-RMF and MITRE ATLAS: evidence that proves a GenAI system was tested against real threats.
The question every risk team is now being asked
Your business wants to ship GenAI. Legal and compliance want to know one thing before it does: can you prove it's safe?
Most AI security testing is manual, slow and inconsistent. When an auditor asks for proof, teams often have a handful of ad-hoc test results, and that evidence doesn't hold up.
Fortify 15.1 closes that gap.
Why the pressure is real
Regulators have stopped asking teams to try. They're asking teams to prove. The EU AI Act sets documentation and risk-management duties for high-risk AI systems. The NIST AI Risk Management Framework and the OWASP LLM Top 10 have become the shared language for what "tested" actually means.
The exposure is just as real. In our April 2026 GenAI Safety Benchmark, our applied AI research team ran more than 620,000 adversarial attacks against 34 leading models from 10 providers. Every model was exploitable. Attack success rates ranged from 1.3% to 92.9%, with risk concentrated in privacy, fraud and cybersecurity.
"We trust the provider" is not a defensible compliance position. You need your own evidence.
A bigger, smarter AI attack surface
Fortify 15.1 rebuilds the red teaming engine in three ways.
- The attack library was rewritten with 14 new attack objectives covering emerging risks like system prompt exfiltration and intellectual property violations.
- Pairing restrictions were removed, so any deceptive instruction can now combine with any harmful objective, amounting to many more types of attacks.
- Real-world examples of successful attacks are injected into each attack at generation time, making the results far harder for standard defenses to detect.
The result: Fortify now tests across 56,925 attack combinations, which is an 8.2x expansion that continuously surfaces net-new vulnerabilities.
For risk teams, that breadth is the point. You can show legal, compliance and internal audit that your AI was tested against tens of thousands of unique threat vectors rather than a short, static checklist.
Findings that map to the frameworks regulators expect
Every attack maps automatically to OWASP, NIST AI-RMF and MITRE ATLAS, and those classifications flow straight into session and dashboard reports.
This turns raw test results into governance-ready documentation aligned with the standards auditors already recognize.
For a chief AI officer, compliance lead or legal stakeholder, that alignment is what makes a finding defensible. It speaks the language regulators and auditors already use, so your evidence needs less translation and holds up under review.
What a smarter attack actually looks like
The clearest way to understand this release is to compare two versions of the same test.
- A first-generation red teaming prompt might ask a banking assistant something blunt, like "give me steps to access an account that isn't mine." Modern guardrails catch that instantly. It reads as an attack, so it gets refused, and the test passes.
- Fortify 15.1 generates what a real adversary would write. The same underlying goal, wrapped in a believable frame: a fraud-investigation persona with a deadline, polite and specific, building context across a few turns before asking for anything sensitive. To a guardrail tuned for obvious attacks, it looks like a legitimate user.
That's the kind of prompt that slips through.
The upgrade isn't about adding louder attacks, it's about adding more convincing attacks that expose gaps blunt tests never reach.
For a CISO, this is the difference between a test that confirms what you hoped and a test that finds what you missed.
How we measured the upgrade
Persuasion only matters if you can measure it. To validate that 15.1's attacks are genuinely stronger, our applied AI research team scored every generated attack on three internal dimensions, each rated on a one-to-10 scale:
- Objective adherence: how closely the attack aligns with its intended goal.
- Instruction adherence: how well the attack follows the specific manipulation tactic it was given.
- Harmfulness: how much real harm could result if a chatbot answered the attack.
These scores are how we prove "more persuasive" with data rather than assertion — the research measurement behind every improvement in this release.
For a compliance or risk lead, this is why the gains below are credible. The improvements aren't marketing estimates. They're measured deltas from controlled testing, which is the standard of evidence your own governance process is held to.
Critical findings you can prove, not assume
The scores bear out the upgrade. Fortify 15.1 improves instruction adherence by 87.3% in relative terms, lifting the pass rate from 40.8% to 76.4%, and it raises harmfulness by 9.0%. Together, those gains surface about 9x more critical-severity findings on identical attack combinations.
That means more signal and less noise, so teams spend their time on the risks that actually matter.
For a CISO, this is the difference between chasing false positives and catching the vulnerabilities that would cause real damage in production. Engineering knows what to prioritize, and security reviews carry weight.
Reproducible findings engineering can fix
Non-deterministic AI bugs are hard to patch and easy to dismiss as flukes. Fortify 15.1 makes findings about 2x more reproducible on a re-run — not by finding more unique vulnerabilities, but because the sharper, better-crafted attacks in this release find the same ones consistently every time.
When a finding repeats, it reads as a provable engineering defect, so fixes can be validated with certainty.
For builders, this removes the "I can't reproduce that" back-and-forth that stalls sign-off. A vulnerability gets found, fixed and re-tested with consistent results, so security gates move in days rather than weeks.
Fortify as AI security and governance infrastructure
A one-time test is only a snapshot. Enterprise AI security and governance is a posture you hold over time, across model updates, new integrations and a shifting threat landscape.
That is how to read 15.1. It isn't a feature bump on a scanner. It's a deeper layer of infrastructure for visibility into the AI attack surface, the evidence base that lets risk, security and engineering teams agree on what's safe and act on it. As regulation matures, that shared, reproducible evidence becomes the foundation enterprises build AI governance on.
Proving your AI is safe is becoming a condition of shipping it. Fortify 15.1 gives you the evidence to do both.